中国象棋Zero(CCZero)是一个开源项目,把AlphaZero的算法应用到了中国象棋上,旨在借助广大象棋爱好者之力一起训练出一个可以打败旋风名手的“象棋之神”。因为种种原因吧,这个目标到目前(2018/11/07)为止未能实现,或者说还差得远,而跑谱的人也越来越少了,很可能坚持不了多久了。
虽然未能实现目标,但在技术上还是有一定意义的,GitHub上也时不时有人询问技术细节,在此总结一下,记录一些坑以后不要再踩。
模块
程序主要分为三大模块(每个模块对应一个目录):
agents:核心模块,决定如何下棋model.py:神经网络模型player.py:MCTS,输出走法api.py:供外界调用model
envrionment:象棋规则- 训练(跑谱)使用
static_env.py,速度快一些 - 用自带GUI下棋时使用的是
env.py,chessboard.py这些,可以输出PNG格式的棋谱
- 训练(跑谱)使用
worker:把agent和envrionment串联起来的脚本self_play.py:自我博弈compute_elo.py:评测并上传结果到官网optimize.py:训练棋谱_windows后缀表示是在Windows平台上运行的相应功能,之所以分开是因为两个多进程的启动方式不同,导致代码结构也要发生一些变化,详见自我博弈。
神经网络模型
网络输入:\(14\times10\times9\)
- \(10 \times 9\) 是中国象棋棋盘的大小
- \(14\) 是所有棋子种类(红/黑算不同种类)
- 整体的输入就是14个棋盘堆叠在一起,每个棋盘表示一种棋子的位置:棋子所在的位置为1,其余位置为0。
网络输出
- 策略头(policy head)输出:\(2086\)
- \(2086\) 是行动空间的大小。行动空间就是说根据中国象棋的规则,任意棋子在任意位置的走法集合。
- 价值头(value head)输出:\(1\)
- 价值头输出一个标量衡量当前局势 \(v\in[-1, 1]\):当 \(v\) 接近1时,局势大好;接近0为均势;接近-1为败势。
附:棋子编号表
| 棋子 | 编号 |
|---|---|
| 兵/卒 | 0 |
| 炮 | 1 |
| 车 | 2 |
| 马 | 3 |
| 相/象 | 4 |
| 仕/士 | 5 |
| 帅/将 | 6 |
网络结构
网络主体是 ResNet,输出部分分出两个头,分别输出 policy 和 value。现在的架构是中间有10个残叉块(Residual Block),每个块里面有两个CNN:卷积核大小为 \(3 \times 3\),过滤器个数为192。
蒙特卡洛树搜索
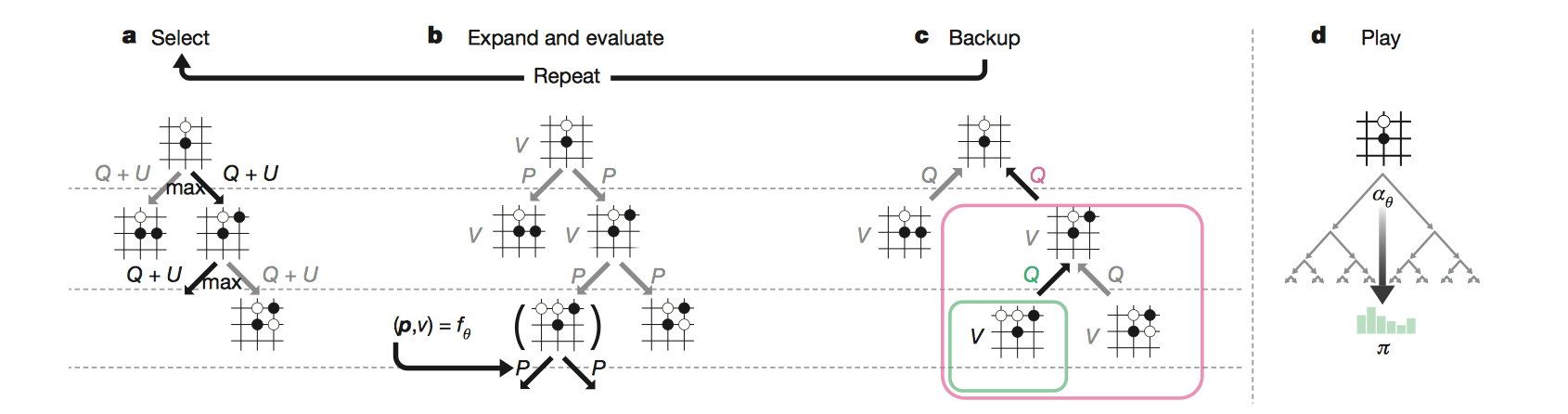
搜索树中的每个节点都包含所有合法移动 a ∈ A(s) 的边(s,a)。 每条边存储一组统计数据, \[ \{N(s,a) ,W(s,a) ,Q(s,a) ,P(s,a)\} \] 其中 \(N(s,a)\) 是访问计数,\(W(s,a)\) 是总动作价值,\(Q(s,a)\) 是平均动作价值,\(P(s,a)\) 是选择该边的先验概率。 多个模拟在单独的搜索线程上并行执行。
选择
每个模拟的第一个 in-tree 阶段开始于搜索树的根节点 \(s_0\),并且在模拟时刻 L 处到达叶节点 \(s_L\) 时结束。在每个这些时刻 \(t < L\) 处,根据搜索树中的统计量选择一个移动: \(a_t = \arg\max_a(Q(s_t,a) + U(s_t,a))\),其中 \(U(s_t,a)\) 使用PUCT算法的变体得到 \[ U(s,a)=c_{puct}P(s,a)\frac{\sqrt{\sum_bN(s,b)}}{1+N(s,a)} \] 其中 \(c_{puct}\) 是一个决定探索程度的常数; 这种搜索控制策略最初倾向于具有高先验概率和低访问次数的行为,但后期倾向于具有高动作价值的行为。
扩展和评估
叶子结点 \(s_L\) 被加入到等待评估队列进行评估: \((d_i(p),v)=f_\theta(d_i(s_L))\),其中 \(d_i\)是旋转或反射操作。神经网络一次评估队列里的 8 个结点;搜索进程直到评估完毕才能继续工作。每个叶子结点和每条边 \((s_L,a)\) 的统计值被初始化为 \(\{N(s_L,a) = 0,W(s_L,a) = 0,Q(s_L,a) =0, P(s_L, a) = p_a\}\),然后价值 v 开始回溯。
回溯
每条边的统计值延路径反向更新:访问计数递增 \(N(s_t,𝑎_t) = N(s_t,𝑎_t) +1\),移动价值更新为平均值 \(W(s_t,a_t)=W(s_t,a_t)+v\), \(Q(s_t,a_t)=\frac{W(s_t,a_t)}{N(s_t,a_t)}\)。
下棋
在搜索结束时,AlphaGo Zero 在根位置 \(s_0\) 选择移动 a,与其指数访问计数成比例,\(\pi(a|s_0) = \frac{N(s_0,a)^{1/\tau}}{\sum_bN(s,b)^{1/\tau}}\),其中 \(τ\) 是控制探索水平的参数。搜索树可以在后面的时刻重用:与所选择的移动对应的子节点成为新的根节点; 在这个节点下面的子树被保留以及它的所有统计数据,而树的其余部分被丢弃。
实现细节
在选择的过程中,发现当前state在history中出现过(形成循环)怎么办?
- 根据比赛规则:闲着循环3次判和;违规(长捉、长将等)判负;对方违规判胜。
Virtual Loss
多线程搜索时,当某一线程选择了某个action时,为了鼓励其他线程选择其他action,应该降低该action的价值(施加virtual loss)
1
2
3
4
5self.tree[state].sum_n += 1
action_state = self.tree[state].a[sel_action]
action_state.n += virtual_loss
action_state.w -= virtual_loss
action_state.q = action_state.w / action_state.n在回溯时,更新value要考虑到virtual loss的影响
1
2
3
4
5node = self.tree[state]
action_state = node.a[action]
action_state.n += 1 - virtual_loss
action_state.w += v + virtual_loss
action_state.q = action_state.w / action_state.n
state表示
虽然对于神经网络来说state就是\(14\times10\times9\)的tensor,但是对于搜索树来说,显然不能用它来表示每个局面。
在初始版本中,象棋环境(environment/chessboard.py)里是用数组来表示棋盘的,所以在搜索中也使用相应的数组表示state,这样做虽然没什么问题,但是在搜索的过程中需要大量的深拷贝操作(因为需要回溯),增加了许多开销。
后来版本进行了改进,使用FEN string作为state的表示,降低了拷贝操作的开销;同时也优化了象棋环境(environment/static_env.py),可以直接对FEN进行操作,无需记录复杂的数组。
Forsyth–Edwards Notation (FEN) is a standard notation for describing a particular board position of a chess game. The purpose of FEN is to provide all the necessary information to restart a game from a particular position.
自我博弈
为了提高CPU/GPU利用率,这里使用了多进程,每个进程各自进行自我博弈。Python的多进程有三个实现方式:fork, spawn, forkserver。
On Windows only
'spawn'is available. On Unix'fork'and'spawn'are always supported, with'fork'being the default.
由于我自己在macOS/Linux上开发和测试,所以首先实现的是基于fork的多进程,而当我在程序加了mp.set_start_method('spawn')的时候,程序就跑不了了,会报pickling error(貌似是因为传给子进程的参数里不能出现queue的数据结构),于是只能换种方式实现来绕过这个问题。
分布式
起初我是没打算做成分布式的,实现完上面说述模块之后我用实验室的K80进行训练,练了几天之后发现进步并不明显,几乎还是随机下,很弱智,这是我才意识到即使把它训练到一个业余玩家的水平也需要巨大的算力。
后来有一天有人在GitHub上提了一个issue说你可以把它做成分布式的,像LeelaZero那样,我们可以帮你一起训练。LeelaZero是国外一个开发者复现AlphaGo论文搞的围棋AI,因为DeepMind并没有公开程序或代码,所以他想训练出一个公开的围棋之神,然后就邀请网友帮他一起训练,具体的方法就是:网友们在自己的机器上进行自我博弈,然后把博弈的棋谱上传到他的服务器上,然后他攒够一定棋谱之后进行训练神经网络,训练好之后分发新的权重。
在国内也有很多人帮他训练(跑谱),给我提issue的那个人也是帮LeelaZero训练中的一员。当时正好程序写完了没什么事做,每天就只能等训练结果,然后就决定尝试一下这个模式。因为之前有过Web开发的经验,所以服务器很快就搭好了,测试基本没问题之后就开始运行。
架构
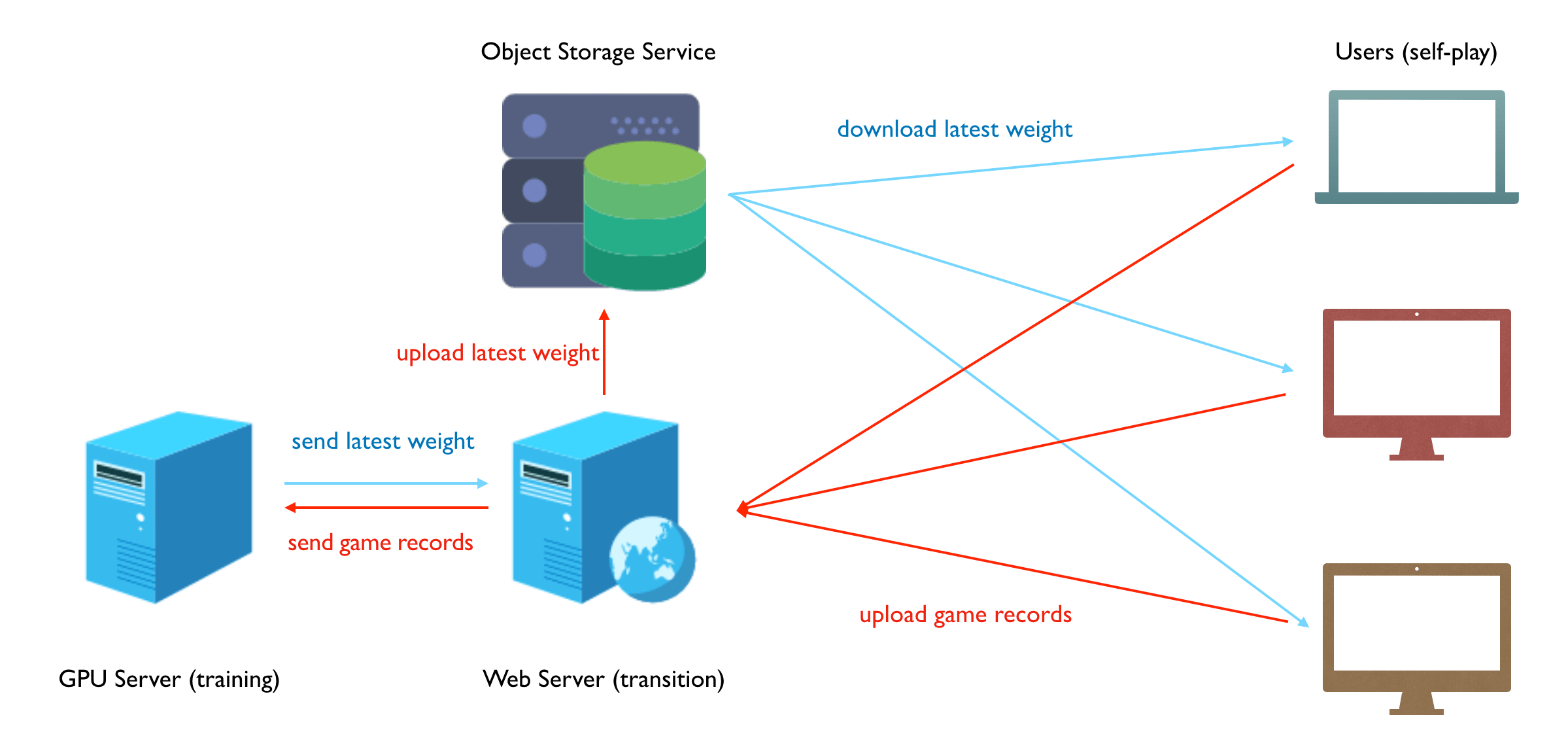
在维护这个项目正常运行的过程中遇到很多坑,程序也做了很多改进:
- 首先是帮忙跑谱的大多都是象棋爱好者,并非开发者,所以我要把Python代码打包成exe文件分发给他们一键执行,最终使用PyInstaller打包成功,这其中遇到了很多坑:
- 卸载cytoolz;pandas的版本必须为0.20.3
- 代码里加上
mp.freeze_support(),否则多进程不会正常工作
- 服务器带宽有限,客户端下载权重太慢,解决办法:把权重放到云存储服务中,如腾讯云/七牛云的对象存储服务。
- 中国象棋棋规的完善。并不是说基础的马走日象走田这种规则,而是像长将、长捉等这种比赛规则,这个算是坑最大的一个,直到现在规则还存在少许问题。
- 部分支持了UCI协议。这样就可以使用其他的象棋界面加载这个引擎,并且能和其他引擎对弈。
- 因为“同行竞争”,我的服务器在今年暑假期间我的服务器经常遭受DDos攻击,由于买不起腾讯云的高防服务,只能尝试其他办法,包括配置弹性IP、配置防火墙、Cloudfare CDN等,但都不好用。最终把服务转移到OVH提供的VPS上才解决了问题(OVH提供免费的DDos防护)。
AlphaZero and ExIt
Expert Iteration(ExIt)是一种模仿学习(Imitation Learning, IL)算法,普通的 IL 算法中,徒弟模仿专家的策略只能提高自己的策略,专家是不会有任何提高的,而 ExIt 算法就是想让师傅教徒弟的时候自己也有提高。
ExIt 算法 师傅根据徒弟的策略进行前向搜索(例如MCTS,alpha-beta,贪心搜索等),得出比徒弟更好的策略,然后徒弟再学习师傅的策略,如此循环,随着徒弟的增强,师傅也会越来越强。

可见,AlphaZero也属于 ExIt 算法,师傅为 MCTS,徒弟就是神经网络。