目录
元数据管理
元数据描述件系统组织结构的数据(描述数据的数据),即访问数据之前必须访问的数据的描述信息和空间组织信息。
- OBS(Object-based Storage,对象存储),OSD(Obeject-based Storage Device,对象存储设备)
- 在OBS系统中,元数据分为物理视图(约占元数据总量90%)和逻辑视图(约占元数据总量10%)。
- 物理视图负责将对象的逻辑块映射到存储物理介质,以支持对象在块存储设备上的工作,存放在OSD上
- 逻辑视图用于描述整个系统的命名空间、目录层次结构和访问控制策略,将文件映射为存储对象,存放在MDS上。
- 存储在OSD中的元数据负责OSD上局部的数据管理
- 而MDS上维护管理的元数据则负责整个存储系统中全局的数据布局、负载调度与访问控制是OBS元数据管理的重点
元数据表
- 用来描述文件与对象之间的对应关系
- flag为0表示一个文件对应多个对象,索引号字段表示各对象在文件中的物理逻辑顺序,偏移值字段表示该对象在对应文件中的偏移首地址
- flag为1则表示多个文件存在一个对象中,索引号字段表示各文件在对象中的物理逻辑顺序,偏移值字段表示各文件在中该对象的偏移首地址
- OSD号是各存储设备(OSD)在OBS存储系统中的全局唯一标识
- 对象号则是根据一定的命名规则形成的对象标识符,通常是一个全局唯一的128位无符号数
MDS的基本功能
- 维护全局树形目录结构
- 提供给客户统一的目录视图
- 完成客户端提交的文件请求到对象的映射
- 并给出所属对象的存储位置
- 元数据的本地存储管理
- 安全策略
- 对象分布管理:负载均衡
- Cache的一致性维护
元数据管理方式
- 核心问题:元数据在集群上的分配策略
- 合理的分配策略可以使元数据在各MDS上均匀分布,来自客户端的访问负载也可以均衡的分布在各个MDS上,在整个MDS集群中尽量分散热点元数据
- 静态目录子树分割
- 按照传统的文件组织方式,将全局目录树划分为若干子树,每个MDS节点上面维护一个或多个子树,各节点共同组成全局的逻辑视图
- 优点
- 简单
- 最大程度的保留了目录的层次逻辑结构
- 便于利用文件访问的空间局部性
- 用户的文件访问请求只需涉及一台MDS,各个MDS彼此独立
- 缺点
- 若某个目录子树下面的自目录或文件成为访问热点,则存放该目录子树的MDS节点将负载过重,成为MDS集群中的瓶颈
- 当加入或删除MDS节点时,需要人工的调整目录子树的分配,大大限制了MDS集群的可扩展性
- 静态哈希
- 静态哈希方法通过将文件标识符、目录/文件名或其他文件特征值进行哈希运算,映射分配到不同的MDS节点上
- 优点
- 将全局元数据均匀的分配到MDS集群各节点上,不会因为存在热点目录导致MDS负载不均衡
- 客户的文件访问请求,只要经过简单的哈希运算便可以定位到目标MDS
- 缺点
- 由于放弃了系统目录结构的空间局部性,在对子目录进行遍历操作,要涉及MDS中大量节点的工作
- 对子目录进行重命名操作将导致大量元数据迁移;
- 客户端上的Cache也因为不断刷新而降低了命中率
- 集群中加入或删除MDS节点时,必然需要更改哈希函数,将导致MDS集群中元数据的重新分配,大量元数据迁移,因此其可扩展性能很有限
- Lazy Hybrid
- 采用文件的全路径名进行哈希运算,这样相同路径下的所有文件被映射存放到同一MDS上,这些文件的元数据进一步通过哈希分散开来,并使用一个元数据查找表(Metadata Look-up Table,MLT)来记录分布信息
- 优点
- 既保留了一定的目录结构,又充分分散了热点目录下的元数据
- 采用了一种访问控制链表描述文件的安全权限,将目录权限的检查合结合文件的元数据中,不必遍历文件路径的所有目录层次才能确定该文件的访问权限
- 将元数据的更新操作暂存延迟到该元数据再次访问的时候进行,分散MDS的更新负担
- 缺点
- 与静态哈希类似
- 动态目录子树分割
- 将全局目录划分为若干目录子树,分布存储在MDS集群各节点上,当系统中出现热点子目录或目录子树过于庞大时,则采用哈希的方法将该子目录下的所有元数据分配到集群其他MDS节点上。
- 优点
- 最大程度保留目录结构,以便充分利用文件的空间局部性
- 动态的进行元数据迁移,调整集群负载
- 缺点
- 在文件访问负载不断变化的情况下,如何能使系统根据负载情况自适应调整元数据分布,是一个实现难题
- 动态哈希
- 提供了相对负载均衡、弹性更新策略和全生命周期管理三种策略,通过MDS之间的检测,将高负载MDS中的部分元数据向低负载MDS迁移
- 当需添加或移出MDS时
- 采用弹性更新策略进行负载调度
- 全生命周期管理利用缓存发现热点并制作副本
- 分担元数据访问负载
- HBA
- 设计思想是在每个MDS上建立两级布隆过滤器阵列(Bloom-filter arrays),第一级是LRU Bloom-filter,用来记录本地MDS访问最频繁的文件,体积小但查找快;第二级Bloom-filter用来记录本地MDS存储的所有文件,体积大但查找慢。
- 同时,每台MDS还保存了集群中其他MDS节点的两级Bloom-filter,构成了两级记录全局文件分布信息的Bloom-filter阵列
- 当LRU表发生溢出时,LRU替换策略将会在相应LRU BF中触发一个增删操作。
- 当LRU BF的改变超过一个阈值时,该元数据服务器将会向其他所有元数据服务器广播新的LRU BF来更新它在其他服务器的副本
- 优点
- HBA策略不关心元数据的具体分配方式,而是通过将客户请求进行两级Bloom-filter阵列查找快速定向到存储该请求文件元数据的MDS上,提高了访问速度
- 缺点
- 不命中带在的请求广播会增加系统额外负担
- G-HBA
- 引入了分组的概念,将MDS集群根据物理位置等因素分成若干小组,每个小组维持着一个全局的两级Bloom-filter阵列,分布的存储在各MDS节点上
- 优点
- 客户请求到来时,MDS首先查询本地的部分Bloom-filter阵列,命中则直接将请求重定向,否则首先在组内组播查询,若再不命中则在组外广播。这样的设计显著减少了HBA系统中客户请求广播带来的网络负载
元数据管理方式对比
- 静态目录子树分割与静态哈希是最基本的元数据分配策略,管理简单而易于实施,但在目录结构或名称发生变化时会导致大量元数据迁移,MDS集群节点的加入与删除也会导致元数据的重新分配,因此可扩展性较差。
- HBA与G-HBA则为元数据管理发展了一种新的设计思路,既在原有元数据分配策略的基础上建立一个逻辑层,充分利用客户访问的时间局部性,结合Bloom-filter结构的高速查询,使客户请求能够快速定位,显著的分担了MDS的工作负载,提高了MDS集群的整体性能。
- LH策略、动态目录子树分割与动态哈希在前两种基本策略基础上进行了改进,通过使用延迟更新策略、元数据查找表、负载动态调整等方法,使元数据管理获得更有效的管理,但是也不可避免的继承了静态目录子树分割与静态哈希的缺点。
Bloom Filter
误判率为: \[ f = (1- (1-\frac{1}{m})^{nk})^k = (1-e^{-\frac{kn}{m}})^k = (1-p)^k \] 最优的哈希函数个数 \[ g = \ln f = k\ln(1-e^{-\frac{kn}{m}}) \]
\[ \frac{\partial g}{\partial k} = \ln(1-e^{-\frac{kn}{m}}) + \frac{kn}{m}\frac{e^{-\frac{kn}{m}}}{1-e^{-\frac{kn}{m}}} = \ln(1-p) + \frac{kn}{m}\frac{p}{1-p} \]
令\(\frac{\partial g}{\partial k} = 0\),解得:\(k = \frac{m}{n}\ln2\) \[ f_{min} = (1-e^{-\ln2})^{\frac{m}{n}\ln2} = (\frac{1}{2})^{\frac{m}{n}\ln2} = (0.6185)^{\frac{m}{n}} \] 应用
- 字典存储
- 数据库
- 分布式缓存
- P2P/Overlay网络应用
重复数据删除
为什么重复数据删除?
- 高效地节约存储空间,数据保存时间更长,或者备份更多
- 减少网络中数据的传输量,也可以提高备份恢复的性能
- 广域网环境,减少数据传输量的意义就更加明显,可以更容易地实现远程备份或容灾
- 帮助用户节约时间和成本
- 数据的恢复速度更快
- 随着备份存储设备的减少,空间、电力、散热的成本消耗也在降低
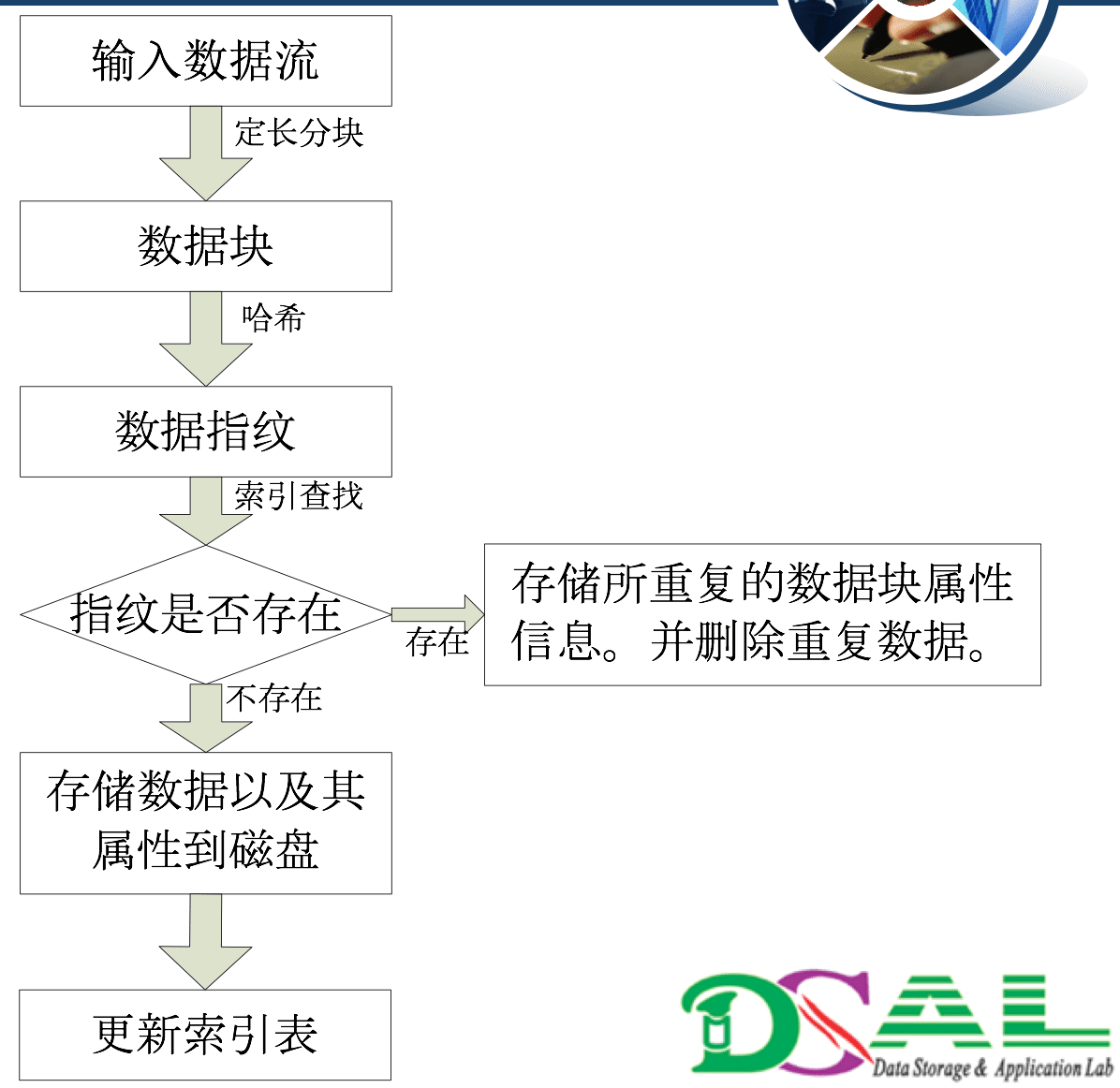
重删流程
- 文件数据流分块。
- 数据块哈希指纹。
- 指纹查找。
- 数据存储
应用
- 备份和归档系统。
- 主存储文件系统。
- 内存的缓存设计。
- 虚拟机存储优化。
重复数据删除的粒度
- 文件级
- 通过检查文件的属性来确定重复文件。
- 这种方法去重的效果不如其他粒度级别
- 但是技术比较简单,而且速度快。
- 数据块级
- 定长分块
- 变长分块
- 将数据切分成大小相同的块。每个块都被赋予一个“指纹”,通过“指纹”与数据索引(指纹库)的比较判断是否为重复数据。
- 如果块分割的越小,块数量相应就越多,索引也就越多。(产生较高的数据去重比率)。
- 不过,我们还要评估一个重要的指标—就是I/O的压力,它与数据比较的频度成正比,加之数据块越小索引就越大,这可能导致备份性能的下降。
- 字节级
- 通过在新旧文件之间进行逐个字节的比较实现的。
- 对性能的影响却非常大。
- 粒度越小,重复数据删除所带来的元数据越多
重复数据删除时间
- 在线机制是指在数据到达存储设备之前对相同的数据进行删除,存储设备上仅存储唯一的不重复的数据。
- 离线的实现机制是事先采用一个磁盘缓冲区,先将所有到达的数据缓暂存到一个磁盘缓冲区中,等所有的数据全部写完之后,在系统空闲的时刻,将磁盘缓冲区的数据重新读取出来再查找和删除其重复的数据。
重复数据删除位置
数据的传输和存储分为两端,一个为数据的发送方,即源端;另一个为数据的接收方和存储方,即目标端。
- 源端重复数据删除。
- 在数据开始传送之前,在源端将重复的数据进行删除,即重复的数据不需要进行传输和存储。
- 目标端重复数据删除。
- 在目标端的存储设备上删除重复的数据。在这种实现机制下,重复数据删除所带来的实现开销全部集中在目标端,源端不需要做任何的有关于重复数据删除的操作。
变长分块分块算法
- 基于内容的分块算法
- Rabin 指纹分块算法
- Hash算法
- MD表示消息摘要(Message Digest,简记为MD),MD5以512比特一块的方式处理输入的消息文本,每个块又划分为16个32比特的子块。算法的输出是由4个32比特的块组成,将它们级联成一个128比特的摘要值。
- 重复删除技术通常采用MD-5 (a 128 字节的散列) 或 SHA-1 (a 160字节的散列) 算法
- 发生散列冲突的概率小于行星碰撞地球
- hash碰撞并不意味着数据会全部丢失。数据被错误识别的这个文件会被破坏。所有其它的数据会被正确地恢复。
问题与挑战
- 可扩展性
- 吞吐率
- 内存开销
- 恢复性能
总结
- 重删分块算法
- 定长&变长
- 分块大小
- 哈希指纹算法
- SHA-1、MD5
- 写吞吐率
- 文件大小
- 哈希算法
- 读性能
- 文件碎片
- 分块算法,仍然继续。
- 哈希摘要,已经成熟。
- 指纹查找,依旧挑战。
- 数据读取,潜在问题。
固态存储技术
半导体存储设备
- 闪存(Flash)
- 电容性
- 相变存储器(PCM)
- 电阻性
SSD优势
- SSD没有机械部件,抗震动
- SSD不需要马达,低能耗
- SSD高性能
- SSD价格在不断下降
固态存储相关技术
- SSD:Solid State Disk 固态盘
- 基本存储介质是NAND FLASH
- 由一个嵌入式控制器控制NAND FLASH的操作
- RAM作为buffer
- 通过IDE,SATA,PCI-e等总线对外提供块接口
- 读请求:块级接口
- 写请求:扇区为单位
- 先擦后写
- 主要模块
- 数据缓存管理模块
- 好的buffer策略能够提高SSD的整体性能
- 闪存翻译层模块 FTL (Flash Translation Layer)
- Address Mapping (地址映射)
- <lsn, size> -> <package,die,plane,block,page>
- 页级映射(好,长,大,大,高)
- 块级映射(差,短,小,小,低)
- 混合映射(较差....)
- Wear leveling (损耗平衡)
- 动态损耗平衡
- 在请求到达时,选取擦除次数较少的块作为请求的物理地址。
- 静态损耗平衡
- 将冷数据从原块取出,存放在擦除次数过多的块,原来存放冷数据的块被释放出来,接受热数据的擦写。
- 动态损耗平衡
- Garbage collection (垃圾回收)
- SSD在使用过程中,会产生大量失效页,在SSD的容量到达一定阈值时,需要调用GC函数,清除所有失效页,以增加可用空间
- Address Mapping (地址映射)
- 数据缓存管理模块
- SCM:Storage-Class Memory 存储级内存
- 非易失
- 零或低空闲能耗
- 类似磁盘一样的容量
- 接近DRAM的存取延迟
- 字节级编址
- 集成SCM的策略
- 缓存策略
- 存储替代策略
- 内存替代混合策略
- 单级存储策略
SSD的接口标准
- 目前:IDE和SATA
- 将来:PCI-E
性能标准
- 测试前提
- 读写比例(R/W:75/25, 50/50)
- 请求块大小(2KB、128KB)
- 测试过程中是否调用过GC操作
- 保留空间是多少(20%)
能耗
- 产品标称上的功率不一定能够反映SSD真实的能耗。因为不同的SSD的内部结构可能有所差别,而且智能的功耗管理系统在SSD实际运行时会对能耗有影响。
- 因此,能反映能耗的指标是:完成相同的IO访问请求,所消耗的总能量,或者是单位能耗所能完成的IO访问数。
自适应的动态缓存管理算法
- 核心思想:利用两次突发性请求周期间的相对空闲时间段,以及固态盘内的空闲资源,提前写回固态盘缓存中的部分数据。
- 提前写回的优势在于:当后续写请求没有命中缓存时,可将之前提前写回的数据直接删除,腾出空间后,将该写请求的数据直接保存在缓存中,避免了实时的缓存数据写回闪存导致这个写请求的延时。
- 组成
- 动态阈值调整算法
- 动态内存分区调整算法
溯源数据的高效存储管理及应用
溯源的概念及研究的意义
- 在系统领域,一个数据的溯源是所有影响这个数据最终状态的进程和数据
- 溯源揭示了数据对象的过去或产生过程,使得人们对复杂的海量数据本身的分析和理解更加透彻
溯源数据的存储
该溯源图信息可用Key-Value数据库(例如BerkeleyDB或Redis),或采用图数据库(例如Neo4j)进行存储。
| 数据库名称 | 数据表记录 |
|---|---|
| ProvenanceDB | <pnode号,属性信息> |
| NameDB | <Name,pnode号> |
| ParentDB | <子pnode号,父pnode号,time> |
| ChildDB | <父pnode号,子pnode号,time> |
溯源的主要应用领域
- 监控加工环节
- 重现实验结果
- 跟踪犯罪行为
- 审计财务账目
- 可以采用溯源存储系统的技术手段来管理物理网中的溯源信息,对实际物品/操作进行管控
- 利用溯源手段,对物联网中的物品进行追踪,是记录物品流向的重要手段
重大挑战:数据量大
- 数据的每次读写操作都会产生溯源数据,从而导致溯源数据量巨大,通常是原始数据量的10倍以上
- 当把一个大的溯源图压缩的足够小到能放在内存中时,对于溯源的高效查询是非常重要的
- 为什么需要压缩?为什么程序运行慢?(内存占比高)
传统数据压缩方法
- gzip: window size 64KB
- bzip2: window size 900KB
- 7Z: window size 1GB
- 缺点:窗口之外的数据无法压缩
- 使用经典的压缩工具,如bzip、zblic等,可以最大限度地压缩溯源,但这些工具导致的溯源信息很难被查询。
迁移压缩
- 将相似的溯源信息重组到一起,再应用压缩器进行压缩
通过挖掘溯源的基本特征来进行压缩
- web压缩和字典编码结合的方法来进行压缩
- 充分分析和挖掘了溯源数据的基本特征
- 充分利用了 web图和溯源图在结构上的相似性,并挖掘了溯源节点属性中所存在的大量重复性的字符串信息
溯源的基本特征
- 溯源数据的组成
- 身份信息 (节点属性)+祖先信息(边上信息)
- 溯源图中包含有大量重复性信息
- 溯源图和web图都具有以下两个特征
- 局部性
- web图:一个网页链接通常会指向同一个URL域中的网页。
- 溯源图:一个进程(溯源节点)依赖于很多库文件,这些库文件通常在同一目录。这些库文件代表的溯源节点编号在同一区段。
- 相似性
- web图:两个邻近的网页很有可能拥有相同的邻居。
- 溯源图: 两个进程(溯源节点)依赖于同一个库文件。
- 局部性
- 溯源数据需要被查询
Web图压缩和字典编码(Web+Dictionary)
- 利用溯源图和web图的相似性,充分挖掘溯源图中数据存在的局部性和相似性,来压缩祖先信息
- 字典编码可将身份信息和祖先信息边上存在的任何重复性字符串进行编码,具有极其灵活以及足够细粒度的编码方式
溯源trace和溯源图,以及web图之间的映射
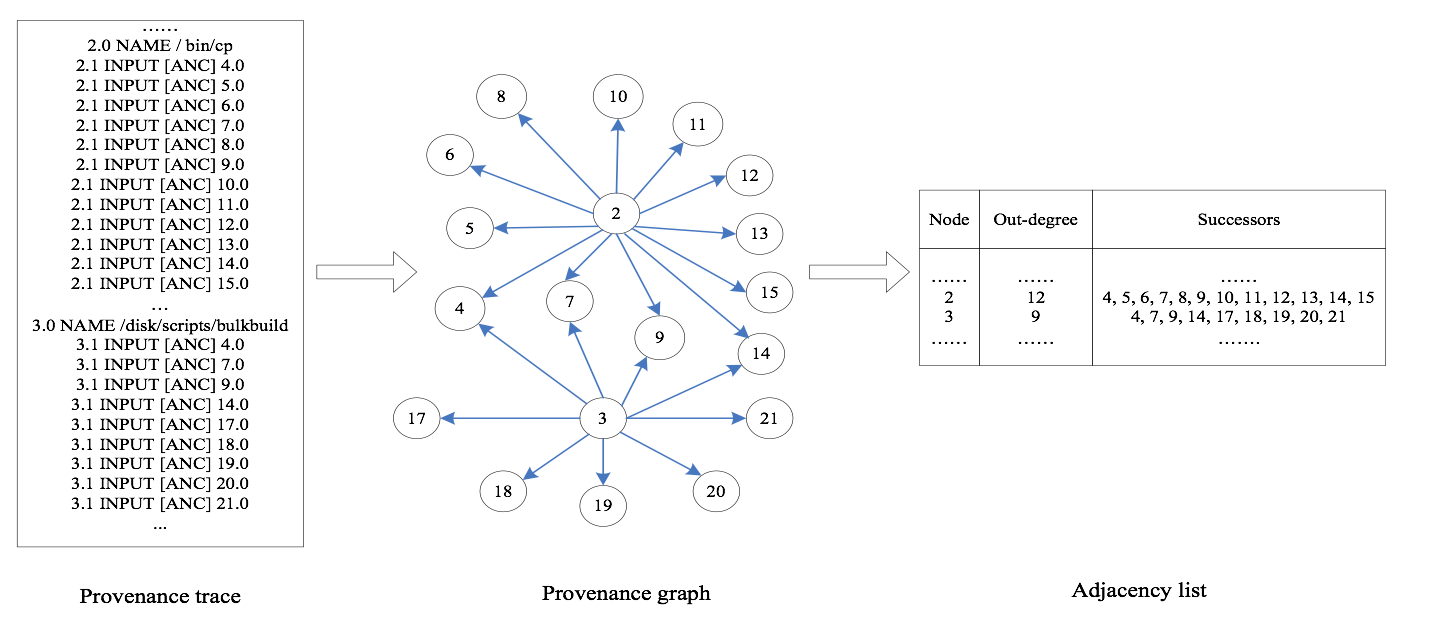
- 溯源trace中的标记“A INPUT[ANC] B” 表示 B是A的一个祖先,这意味着溯源图中有一条从 A 指向 B的边.
web图压缩
溯源数据
- 15.1 INPUT [ANC] 3.1
- 15.1 INPUT [ANC] 11.0
- 15.1 INPUT [ANC] 13.1
- 15.1 INPUT [ANC] 14.1
- 15.1 INPUT [ANC] 17.1
- 16.1 INPUT [ANC] 11.0
- 16.1 INPUT [ANC] 14.1
- 16.1 INPUT [ANC] 19.1
- 16.1 INPUT [ANC] 20.1
- 16.1 INPUT [ANC] 21.1
- 16.1 INPUT [ANC] 33.1
邻接表
Node outd ancestors 15 5 3, 11, 13, 14, 17 16 6 11, 14, 19, 20, 21, 33 寻找相似祖先列表
node outd ref. copy list ancestors 15 5 0=15-15 3, 11, 13, 14, 17 16 6 1=16-15 01010 19, 20, 21, 33 编码连续的祖
#intervals表示有几个连续的串
Left extreme表示跟Node的差距
| node | outd | ref | copy list | inter | left | len | res |
|---|---|---|---|---|---|---|---|
| 15 | 5 | 0 | 1 | -2 | 2 | 3,11,17 | |
| 16 | 6 | 1 | 01010 | 1 | 3 | 3 | 33 |
- 用祖先节点之间的间距进行编码
| node | outd | ref | copy list | inter | left | len | res |
|---|---|---|---|---|---|---|---|
| 15 | 5 | 0 | 1 | -2 | 2 | -12,8,6 | |
| 16 | 6 | 1 | 01010 | 1 | 3 | 3 | 17 |
- 每个节点的编码:\(r\ [b\ B_1 … B_b] i\ E_1 L_1 …E_i L_i R_1 … R_k\)
- r: 参考号
- b: copy list中bit的数量
- \(B_1…B_b\): copy list中bit位的值
- i: interval的个数
- \(E_1…E_i\): Left Extremes
- \(L_1…L_i\): Length
- \(R_1…R_k\): Residuals
字典编码
- 用较小的整数将重复性字符串进行编码
- 可将身份信息上的重复性字符串(如进程执行参数和环境变量)、以及祖先边上的重复性字符串(如时间信息)进行编码
- 具有极其灵活以及足够细粒度的编码方式(可找出相同字符串,或者字符串中的相同前缀、后缀)

入侵检测中的溯源
例子:一个远程的攻击者,通过攻击主机上的vsftpd-2.3.4的backdoor漏洞,获得根用户访问权限。然后入侵者以root权限登陆 shell,并通过vi命令篡改了文件f1和f2。
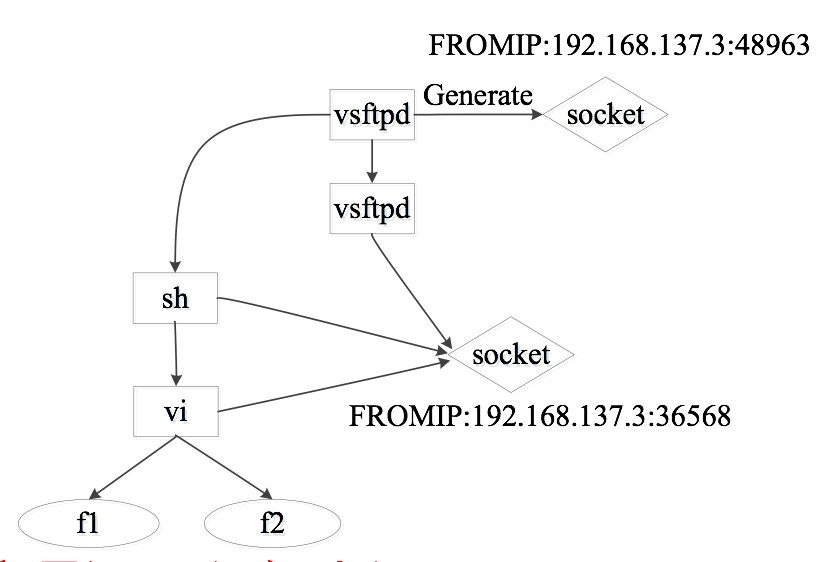
进行计算机取证
- 怎么入侵
- 入侵后都干了什么(修改文件,泄漏秘密,安装后门等)
- 修补系统漏洞,尝试恢复入侵者造成的修改
发现入侵检测点
- 文件系统完整性检查(Tripwire,AIDE)
- 网络检测
- 沙盒
分析入侵行为
- 系统/网络日志(Snort,Ethereal)
- 磁盘状态(The Coroner’s Toolkit)
当前取证方法的不足
- 系统日志记录不够全面,缺乏必要信息
- 网络消息可能被加密
- 磁盘状态仅显示了文件的最终状态
基于溯源的入侵检测总体设计
收集器
- 实时监控应用,生成溯源信息
- 截获系统调用,跟踪收集文件、进程和网络socket的溯源信息
- 修剪大量繁杂的溯源信息来避免误检。
- 使用结构化的key-value 数据库来记录和查询入侵信息
- 溯源数据库
- Pnode节点号唯一的标识了每个对象
- ParentDB 和 ChildDB 分别存储了一个节点的父节点和子节点
- RuleDB 存储了代表对象之间依赖性关系的经常性事件
检测器
从溯源中抽取依赖性信息,建立规则库和检测入侵
规则建立
- 通过存储经常性事件依赖性关系生成规则,并编码规则
- 多次运行一个正常的程序来获取它的溯源信息R
- 对于每个R, 划分为 \(R=\{Dep_1, …Dep_n\}\), 其中\(Dep_i = (A, B)\)表示 A是 B的父节点
- 将每个\(Dep_i\)使用字典编码方法来减少在A和B中重复的字符串
- 将所有这些\(Dep_i\)放进规则库\(G\), 即\(G= \{Dep_1, … Dep_k\}\).

路径匹配
- 基于溯源的路径匹配算法
- 获取所检测程序的溯源信息R, 将它表示为\(R= \{Dep_1, … Dep_n\}\)
- 对于R中的每个\(Dep_i\) , 如果,\(Dep_i = (A, B) \in G\) 则设置它的可疑度\(d_i = 0\), 否则设置可疑度为1
- 寻找R中长度为W的路径, 将路径表示为 \((Dep_1, … Dep_w)\), 将路径决策值p表示为\(p = \frac{\sum_{i=1}^wd_i}{W}\)
- 设置阈值T, 如果 P> T, 则警报会响起,相应的溯源路径会输出, 程序被判断为不正常.
警报输出
- 提供直截了当的入侵路径信息来减少误检和帮助取证分析。
分析器
- 分析入侵的系统漏洞和入侵来源
优化、过滤溯源图
忽略一些特定的对象
比如login进程会读写文件/var/run/utmp,导致新的login进程依赖于之前的login进程;Mount、umount会写文件/etc/mtab,而bash进程在产生时会读取该文件,导致依赖于mount进程;
隐藏只被读的文件
通常是库文件或者配置文件
过滤”辅助”进程
Bash进程产生id进程、consoletype进程和dircolors进程
名词解释
| 中文 | 英文 | 缩写 |
|---|---|---|
| 元数据服务器 | Metadata server | MDS |
| 对象存储 | Object-based Storage | OBS |
| 对象存储设备 | Object-based Storage Device | OSD |
| 元数据查找表 | Metadata Look-up Table | MLT |
| 闪存翻译层 | Flash Translation Layer | FTL |
| 消息摘要 | Message Digest | MD |
| 相变存储器 | Phase-change Memory | PCM |
| 地址映射 | Address mapping | AM |
| 损耗平衡 | Wear leveling | WL |
| 垃圾回收 | Garbage Collection | GC |
| 存储级内存 | Storage-Class Memory | SCM |