隐马尔科夫模型(HMM, Hidden Markov Model)可用标注问题,在语音识别、NLP、生物信息、模式识别等领域被实践证明是有效的算法。
前言
HMM定义
隐马尔可夫模型(HMM)是关于时序的概率模型,描述由一个隐藏的马尔可夫链生成不可预测的状态随机序列,再由各个状态生成观测随机序列的过程。
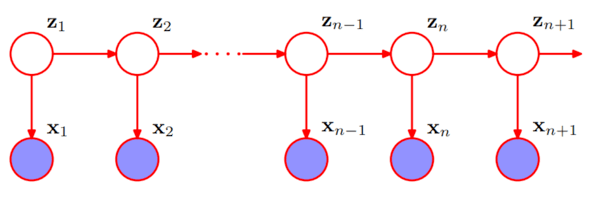
图1. 隐马尔可夫模型的图结构
图1中的 \(z_1, z_2 … z_{n+1}\) 是 \(n+1\) 个不可观测状态,由马尔可夫链连接,称为状态序列;\(x_1, x_2, …, x_{n+1}\) 是由状态序列生成的观测随机序列,称为观测序列。其中,序列中的每个位置可以看作是一个时刻。
马尔可夫链
下面的介绍摘自Wikipedia:
马尔可夫链(英语:Markov chain),又称离散时间马可夫链(discrete-time Markov chain,缩写为DTMC),因俄国数学家安德烈·马尔可夫(俄语:Андрей Андреевич Марков)得名,为状态空间中经过从一个状态到另一个状态的转换的随机过程。该过程要求具备“无记忆”的性质:下一状态的概率分布只能由当前状态决定,在时间序列中它前面的事件均与之无关。这种特定类型的“无记忆性”称作马可夫性质。马尔科夫链作为实际过程的统计模型具有许多应用。
在马尔可夫链的每一步,系统根据概率分布,可以从一个状态变到另一个状态,也可以保持当前状态。状态的改变叫做转移,与不同的状态改变相关的概率叫做转移概率。随机漫步就是马尔可夫链的例子。随机漫步中每一步的状态是在图形中的点,每一步可以移动到任何一个相邻的点,在这里移动到每一个点的概率都是相同的(无论之前漫步路径是如何的)。
回到我们的模型中,由于 \(z_1, z_2, …, z_{n+1}\) 是一条马尔可夫链,所以链中某一状态 \(z_i\) 发生的概率只与 \(z_{i-1}\) 有关,表达成公式就是:
\[P(Z_i = z_i|Z_{i-1}=z_{i-1}, Z_{i-2}=z_{i-2}, …, Z_1 = z_1) = P(Z_i = z_i|Z_{i-1} = z_{i-1})\]
还有一点就是,由于 \(z_2\) 和 \(x_1\) 都是由 \(z_1\) “生成”出来的,所以在不知道 \(z_1\) 的情况下, \(x_1\) 和 \(z_2\) 是不独立的;由于 \(x_2\) 是由 \(z_2\) 生成的,若把 \(x_2\) 和 \(z_2\) 看成一个整体,那么这个整体与 \(x_1\) 也是不独立的;所以在 \(z_1\), \(z_2\) 都不可观察(未知)的前提下,\(x_1\), \(x_2\) 不相互独立。
这一点与其它机器学习算法比如 Logistic Regression, SVM, Decision Tree 等都不一样,那些算法都是假设每个样本相互独立,而HMM就恰恰相反,要求样本间有某种联系。就拿中文分词来举例,正常人说的每一句话里,前一个字和后一个字都应该是有联系的,有的联系很紧密,我们把它认为是一个词语,有的联系不那么强,我们认为是词与词之间的分隔,显然每个字之间都不是独立的。这也就解释了为什么HMM可以用做中文分词而那些算法不可以。
HMM的确定
HMM由初始概率分布 \(\pi\),状态转移概率分布 \(A\) 以及观测概率分布 \(B\) 确定,把它们三个合起来表示成 \(\lambda\),即:\[\lambda = (A, B, \pi)\]
分别来解释一下这三个都是什么东西。
定义 \(Q\) 为所有可能的状态的集合,\(N\) 是所有可能的状态数,即 \(Q=\{q_1, q_2, …, q_N\}\)。
- 对于中文分词的例子来说,可能的状态只有两个:\(0, 1\),\(0\) 表示这个字不是这个词的最后一个字,\(1\) 表示这个字是这个词的末尾,该分割了。所以 \(Q = \{0, 1\}, N = 2\)。
定义 \(V\) 是所有可能的观测的集合,\(M\) 是可能的观测数,即 \(V = \{v_1, v_2, …, v_M\}\)
- 对于中文分词的例子来说,\(V\) 就是语料库里的所有字,而汉字在计算机里实际是用编码表示的,若是两字节编码,则只有 \(2^{16} = 65536\) 种情况,所以 \(M = 65536\)。
再定义 \(I\) 是长度为 \(T\) 的状态序列,\(O\) 是对应的观测序列,即:\(I = \{i_1, i_2, …, i_T\}\ \ O = \{o_1, o_2, …, o_T\}\)。
- 状态序列 \(I\) 对应图1中的 \(z_1, z_2, …, z_n\),观测序列 \(O\) 对应图1的 \(x_1, x_2, … , x_n\),只不过换了个名字。
状态转移概率分布\(A\)
状态转移概率是个什么东西呢,其实就是从一个状态转移到另一个状态的概率,具体来说就是 \(t\) 时刻的隐状态处于状态 \(q_i\),即 \(i_t = q_i\) 的条件下,\(t+1\) 时刻隐状态转换到状态 \(q_j\),即 \(i_{t+1} = q_j\) 的概率,这个就是从 \(q_i\) 转换到 \(q_j\) 的转移概率,定义为 \(a_{ij}\),那么它的公式就是:\(a_{ij} = P(i_{t+1} = q_j|i_t=q_i)\)。
我们总共有 \(N\) 的可能的状态,每个状态都有一定的概率转移到其它的状态,所以状态转移概率应该有 \(N*N\) 个,为方便表示,我们把它写成一个 \(N*N\) 的矩阵,定义为 \(A\),也就是状态转移概率分布,也叫状态转移概率矩阵。
\[A = [a_{ij}]_{N*N}\],其中 \(a_{ij} = P(i_{t+1} = q_j|i_t = q_i)\)
观测概率分布 \(B\)
观测概率又是什么鬼呢,其实也很简单,就是由隐状态 \(i_t\) 生成观测 \(o_t\) 的概率,具体来说就是时刻 \(t\) 处于状态 \(q_i\),即 \(i_t = q_i\) 的条件下,生成观测 \(v_k\) 的概率,记为 \(b_{ik}\),写成公式就是 \(b_{ik} = P(o_t = v_k|i_t=q_i)\)。
由于每个隐状态有 \(N\) 种可能,观测有 \(M\) 种可能,所以观测概率应有 \(M*N\) 个,为方便表示,我们把它写成一个 \(N*M\) 的矩阵,定义为 \(B\),也就是 观测概率分布,也叫观测概率矩阵,又叫发射矩阵或混淆矩阵。
\[B = [b_{ij}]_{N*M}\],其中 \(b_{ik} = P(o_t = v_k|i_t=q_i)\)
初始概率分布 \(\pi\)
所谓初始概率就是在 \(t = 1\) 时刻选择某一状态的概率。如 \(\pi_i\) 是时刻 \(t=1\) 处于状态 \(q_i\) 的概率,即 \(\pi_i = P(i_1 = q_i)\)。
显然应该有 \(N\) 个初始概率,定义 \(\pi\) 为初始概率向量,共有 \(N\) 的元素。
参数总结
HMM由初始概率分布 \(\pi\)、状态转移概率分布\(A\) 以及观测概率分布 \(B\) 确定。因此,HMM可以用三元符号表示,称为HMM的三要素:\(\lambda = (A, B, \pi)\)
HMM的两个基本性质
齐次假设: \[ P(i_t|i_{t-1}, o_{t-1}, i_{t-2}, o_{t-2}, …, i_1, o_1) = P(i_t|i_{t-1}) \] 观测独立性假设: \[ P(o_t|i_t, i_{t-1}, o_{t-1}, …, i_1, o_1) = P(o_t|i_t) \] 这两个性质或者说假设均来自马尔可夫链,在前面也略有提到,应该可以理解吧。
HMM的3个基本问题
不知道大家看到这里是什么感觉,有没有觉得这个模型很怪,心想:这玩意咋训练?
反正我刚学到这的时候是有这种感觉的,这也就引出了HMM的3个最重要的问题:概率计算、学习和预测。
大体来解释一下:
- 概率计算问题:给定模型 \(\lambda = (A, B, \pi)\) 和观测序列 O = {o_1, o_2, …, o_T},计算模型 \(\lambda\) 下观测序列 \(O\) 出现的概率 \(P(O|\lambda)\)
- 学习问题:已知观测序列 \(O=\{o_1, o_2, …, o_T\}\),估计模型 \(\lambda=(A, B, \pi)\) 的参数,使得在该模型下观测序列 \(P(O|\lambda)\) 最大。
- 预测问题:已知模型 \(\lambda=(A,B,\pi)\) 和观测序列 \(O=\{o_1, o_2, …, o_T\}\),求给定观测序列条件概率 \(P(I|O, \lambda)\) 最大的状态序列 \(I\)。
概率计算
目标:给定模型 \(\lambda = (A, B, \pi)\) 和观测序列 O = {o_1, o_2, …, o_T},计算模型 \(\lambda\) 下观测序列 \(O\) 出现的概率 \(P(O|\lambda)\)。
概率计算有三种方法:暴力求解,前向算法和后向算法,后两者实际上式动态规划算法。
暴力算法
算法思想:按照概率公式,列举所有可能的长度为 \(T\) 的状态序列 \(I = \{i_1, i_2, …, i_T\}\),求各个状态序列 \(I\) 与观测序列 \(O=\{o_1, o_2, …, o_T\}\) 的联合概率 \(P(O, I|\lambda)\),然后对所有可能的状态序列求和,从而得到 \(P(O|\lambda)\)。
先求 \(P(O, I|\lambda)\),然后对所有 \(I\) 加和即可。
我们可以把联合概率分解为条件概率的乘积:\(P(O, I|\lambda) = P(O|I, \lambda)P(I|\lambda)\)
状态序列 \(\{i_1, i_2, …, i_T\}\) 的概率怎么求呢?一步一步来。 \[ \begin{array}{lcl} P(I|\lambda) = P(i_1, i_2, …, i_T|\lambda) \\ \ \ \ \ \ \ \ \ \ \ \ \ = P(i_2, …, i_T|\lambda)\cdot P(i_1|\lambda) \\ \ \ \ \ \ \ \ \ \ \ \ \ = P(i_2, …, i_T|\lambda)\cdot \pi_{i_1} \\ \ \ \ \ \ \ \ \ \ \ \ \ = \pi_{i_1} \cdot P(i_3, ..., i_T|\lambda)P(i_2|\lambda) \\ \ \ \ \ \ \ \ \ \ \ \ \ = \pi_{i_1} a_{i_1i_2} \cdot P(i_3, ..., i_T|\lambda) \\ \ \ \ \ \ \ \ \ \ \ \ \ = \ .... \\ \ \ \ \ \ \ \ \ \ \ \ \ = \pi_{i_1} a_{i_1i_2}a_{i_2i_3}...a_{i_{T-1}i_T} \end{array} \] 同理可以求观测序列的概率: \[ P(O|I, \lambda) = b_{i_1o_1}b_{i_2o_2}...b_{i_To_T} \] 所以 \(O\) 和 \(I\) 同时出现的联合概率是: \[ P(O,I|\lambda) = P(O|I, \lambda)P(I|\lambda) = \pi_{i_1}b_{i_1o_1}a_{i_1i_2}b_{i_2o_2}...a_{i_{T-1}i_T}b_{i_ToT} \] 对所有可能的状态序列 \(I\) 求和,得到观测序列 \(O\) 的概率: \[ P(O|\lambda) = \sum_I P(O, I|\lambda) = \sum_{i_1, i_2, ..., i_T}\pi_{i_1}b_{i_1o_1}a_{i_1i_2}b_{i_2o_2}...a_{i_{T-1}i_T}b_{i_ToT} \] 这样就求解出观测序列 \(O\) 的概率,也不是很难,不是吗?
接下来我们来分析一下这个算法的时间复杂度。
由于要穷举所有 \(I\) 的可能性, \(I\) 的长度是 \(T\),每个 \(i\) 有 \(N\) 种可能性,所以总共有 \(N^T\) 个 \(I\)。计算每个 \(I\) 需要做 \(2T\) 次乘法,因此,时间复杂度为 \(O(TN^T)\),超级高。
前向-后向算法
我们思考一个问题,我们在求最长递增子序列、最大连续子数组或是KMP中next数组的计算,无不用到同一个思想:在前 \(k\) 个已知的情况下求第 \(k+1\) 个。
我们借鉴这种优化思想来定义两个概念:前向概率和后向概率。
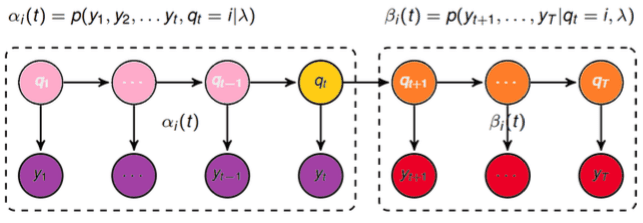
图2:前向概率和后向概率示意图
定义前向概率 \(\alpha_t(i)\) 为 \(t\) 时刻下隐状态为 \(q_i\) 并且观测到观测序列 \(o_1, o_2, …, o_t\) 的概率,即 \[ \alpha_t(i) = P(o_1, o_2, ..., o_t, i_t = q_i|\lambda) \] 其中,\(o\) 等于图2中的 \(y\),\(i\) 等于图2中的 \(q\),和我们之前的定义相同。
同理定义后向概率 \(\beta_t(i)\) 为已知 \(t\) 时刻的状态为 \(q_i\),观测到输出序列为 \(o_{y+1}, …, o_T\) 的概率,即: \[ \beta_t(i) = P(o_{t+1}, o_{t+2}, ..., o_T|i_t = q_i, \lambda) \] 前向算法
思想:递推计算前向概率 \(\alpha_t(i)\) 及观测序列概率 \(P(O|\lambda)\)。
初值:\(\alpha_1(i) = P(o_1, i_1=q_i|\lambda) = \pi_ib_{io_1}\)
递推:对于 \(t = 1, 2, …, T-1\), \[ \begin{array}{lcl} \alpha_{t+1}(i) = P(o_1, ..., o_{t+1}, i_{t+1}=q_i|\lambda) \\ \ \ \ \ \ \ \ \ \ \ \ \ = (\sum_{j=1}^N P(o_1, ..., o_t, i_t=q_j|\lambda) \cdot a_{ji})\cdot b_{io_{t+1}} \\ \ \ \ \ \ \ \ \ \ \ \ \ = (\sum_{j=1}^Na_t(j)a_{ji})b_{io_{i+1}} \end{array} \] 最终:\(P(O|\lambda) = \sum_{i=1}^N\alpha_T(i)\)
我们再分析一下该算法的复杂度,每计算一个 \(\alpha_T(i)\) 需要 \(T\) 次迭代,每次迭代需要计算约 \(N\) 次乘法,共计算 \(N\) 次,因此,前向算法的时间复杂度为 \(O(N^2T)\)。
相比于暴力求解,通过递推的方式大大降低了时间复杂度,原因在于暴力求解重复计算了好多东西,而递推公式每一步都可以利用上一步的结果。
后向算法
思想:和前向算法类似,也是递推的思想。
初值:\(\beta_T(i) = 1\)
递推:对于 \(t = T-1, T-2, …, 1\) \[ \begin{array}{lcl} \beta_t(i) = P(o_{t+1}, ..., o_T|i_t = q_i, \lambda) \\ \ \ \ \ \ \ \ \ = \sum_{j=1}^N(P(o_{t+2}, ..., o_T|i_{t+1}=q_j, \lambda) \cdot a_{ji}b_{jo_{t+1}}) \\ \ \ \ \ \ \ \ \ = \sum_{j=1}^N(a_{ji}b_{jo_{t+1}}\beta_{t+1}(j)) \end{array} \] 最终:\(P(O|\lambda) = \sum_{i=1}^N\pi_ib_{io_1}\beta_1(i)\)
同理后向算法的时间复杂度也是 \(O(N^2T)\)。
前后向关系
我们计算一下观测到观测序列 \(O\) 并且 \(t\) 时刻的状态为 \(q_i\) 的概率: \[ \begin{array}{lcl} \ \ \ \ P(i_t = q_i, O|\lambda) \\ = P(O|i_t = q_i, \lambda)P(i_t = q_i|\lambda)\\ = P(o_1, ..., o_t, o_{t+1}, ...., o_T|i_t=q_i,\lambda)P(i_t=q_i|\lambda)\\ = P(o_1, ..., o_t|i_t=q_i, \lambda)P(o_{i+1}, ..., o_T|i_t=q_i,\lambda)P(i_t=q_i|\lambda)\\ = P(o_1, ..., o_t, i_t=q_i|\lambda)P(o_{i+1}, ..., o_T|i_t=q_i,\lambda)\\ = \alpha_t(i)\beta_t(i) \end{array} \] 正好等于 \(\alpha\) 和 \(\beta\) 的乘积,是不是很有意思。
单个状态的概率
我们定义单个状态的概率为 \(\gamma_t(i)\),即给定模型 \(\lambda\) 和观测 \(O\),在时刻 \(t\) 处于状态 \(q_i\) 的概率,写成公式就是: \[ \gamma_t(i) = P(i_t = q_i|O, \lambda) \] 用上前面的结论进一步推导一下: \[ \gamma_t(i) = P(i_t=q_i|O,\lambda)=\frac{P(i_t=q_i,O|\lambda)}{P(O|\lambda)}=\frac{\alpha_t(i)\beta_t(i)}{\sum_{i=1}^N\alpha_t(i)\beta_t(i)} \] 所以求它为了干嘛???
当然是有用的了,我们想想 \(\gamma_t(i)\) 代表了啥,是给定模型 \(\lambda\) 和观测 \(O\),在时刻 \(t\) 处于状态 \(q_i\) 的概率。那我们可以把时刻 \(t\) 处于所有状态的概率都求出来,然后取一个最大的作为预测值,对所有时刻都这么做,从而得到一个状态序列 \(I^*=\{i_1^*, i_2^*, …, i_T^*\}\),将它作为预测结果,这不就解决了预测问题吗!
两个状态的联合概率
定义两个状态的联合概率 \(\xi_t(i,j)\) 为给定模型 \(\lambda\) 和观测 \(O\),在时刻 \(t\) 处于状态 \(q_i\) 且时刻 \(t+1\) 处于状态 \(q_j\) 的概率,即: \[ \xi_t(i,j) = P(i_t = q_i, i_{t+1}=q_j|O, \lambda) \] 进一步推导: \[ \begin{array}{lcl} \xi_t(i, j) = P(i_t = q_i, i_{t+1}=q_j|O, \lambda) \\ \ \ \ \ \ \ \ \ \ \ \ = \frac{P(i_t=q_i, i_{t+1=q_j},O|\lambda)}{P(O|\lambda)}\\ \ \ \ \ \ \ \ \ \ \ \ = \frac{P(i_t=q_i, i_{t+1=q_j},O|\lambda)}{\sum_{i=1}^N\sum_{j=1}^NP(i_t=q_i, i_{t+1=q_j},O|\lambda)} \end{array} \] 其中,\(P(i_t=q_i, i_{t+1=q_j},O|\lambda) = \alpha_t(i)a_{ij}b_{jo_{t+1}}\beta_{t+1}(j)\)。
期望
在观测 \(O\) 下状态 \(i\) 出现的期望: \[ \sum_{t=1}^T\gamma_t(i) \] 在观测 \(O\) 下状态 \(i\) 转移到状态 \(j\) 的期望: \[ \sum_{t=1}^{T-1}\xi_t(i, j) \]
这些都是在为后面做铺垫。
学习算法
HMM的学习方法分为监督学习和无监督学习两种。
- 若训练数据包括观测序列和壮态序列,则HMM的学习非常简单,是监督学习;
- 若训练数据只有观测序列,则HMM的学习需要使用EM算法,是非监督学习。
监督学习
Bernoulli大数定理
一言以概:频率的极限是概率。
学习方法
HMM的监督学习方法很简单,而且有点无趣,直接统计就行,这里直接列出公式。
初始概率 \[ \hat{\pi_i} = \frac{|q_i|}{\sum_i|q_i|} \] 转移概率 \[ \hat{a_{ij}} = \frac{|q_{ij}|}{\sum_{j=1}^N|q_{ij}|} \] 观测概率 \[ \hat{b_{ik}} = \frac{|s_{ik|}}{\sum_{k=1}^M|s_{ik}|} \]
Baum-Welch 算法
若训练数据只有观测序列,则HMM的学习需要使用EM算法,是非监督学习。
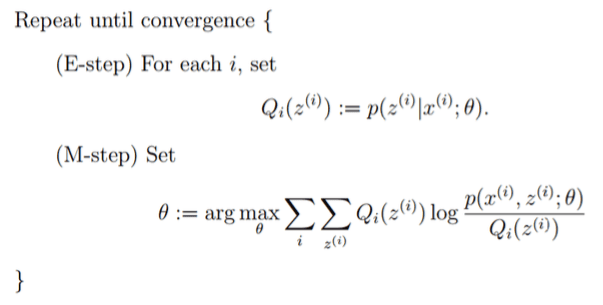
图3.EM算法框架
所有观测数据写成 \(O = (o_1, o_2, …, o_T)\),所有隐数据写成 \(I=(i_1,i_2, …, i_T)\),完全数据是 \((O, I) = (o_1, o_2, …, o_T, i_1, i_2, …, i_T)\),则完全数据的对数似然为 \(\ln P(O,I|\lambda)\)。
设 \(\overline{\lambda}\) 是HMM参数的当前估计值,\(\lambda\) 为待求的参数,则EM算法中的 \(Q\),即条件概率为: \[ \begin{array}{lcr} Q(\lambda, \overline{\lambda}) = P(I|O,\overline{\lambda})\\ \ \ \ \ \ \ \ \ \ \ \ \ \ = \frac{P(O,I|\overline{\lambda})}{P(O|\overline{\lambda})}\\ \ \ \ \ \ \ \ \ \ \ \ \ \ \propto P(O,I|\overline{\lambda}) \end{array} \] EM算法中的M步为: \[ \lambda = \arg\max_\lambda \sum_IP(O,I|\overline{\lambda})\cdot \ln P(O,I|\lambda) \] 根据暴力算法中的计算结果: \[ P(O,I|\lambda) =\pi_{i_1}b_{i_1o_1}a_{i_1i_2}b_{i_2o_2}...a_{i_{T-1}i_T}b_{i_ToT} \] 化简得: \[ \begin{array}{lcr} \ \ \ \sum_IP(O,I|\overline{\lambda})\cdot \ln P(O,I|\lambda)\\ = \sum_I\ln \pi_{i_1}P(O,I|\overline{\lambda})\\ + \sum_I(\sum_{t=1}^{T-1}\ln a_{i_ti_{t+1}})P(O,I|\overline{\lambda})\\ + \sum_I(\sum_{t=1}^T\ln b_{i_to_t})P(O,I|\overline{\lambda}) \end{array} \] 接下来就是极大化上面的式子,求得参数 \(A, B, \pi\)。
由于该三个参数分别位于三个项中,可分别极大化。
先求 \(\pi\) 看看:\(\sum_I\ln \pi_{i_1}P(O,I|\overline{\lambda}) = \sum_{i=1}^N\ln \pi_{i}P(O,i_1=i|\overline{\lambda})\),注意到 \(\pi_i\) 满足加和为 \(1\),利用Lagrange乘数法,构造Lagrange函数得: \[ L(\pi_i, \gamma) = \sum_{i=1}^NP(O,i_1=i|\overline{\lambda}) + \gamma(\sum_{i=1}^N\pi_i - 1) \] 其中,\(\gamma\) 为Lagrange乘子,对 \(L\) 求偏导并令其等于零,得到: \[ P(O,i_1=1|\overline{\lambda}) + \gamma\pi_i = 0 \] 对所有 \(i\) 求和,得到: \[ \gamma = -P(O|\overline{\lambda}) \] 把 \(\gamma\) 代回上式,得到初始状态概率: \[ \pi_i = \frac{P(O,i_1=1|\overline{\lambda})}{P(O|\overline{\lambda})} = \frac{P(O,i_1=i|\overline{\lambda})}{\sum_{i=1}^NP(O,i_1=i|\overline{\lambda})} = \frac{\gamma_1(i)}{\sum_{i=1}^N\gamma_1(i)} \] 对于转移概率和观测概率,用同样的方法,可以得到: \[ a_{ij} = \frac{\sum_{t=1}^{T-1}P(O,i_t=i, i_{t+1}=j|\overline{\lambda})}{\sum_{t=1}^{T-1}P(O,i_t=i|\overline{\lambda})} = \frac{\sum_{t=1}^{T-1}\xi_t(i,j)}{\sum_{t=1}^{T-1}\gamma_t(i)} \]
\[ b_{ik} = \frac{\sum_{t=1}^TP(O,i_t=i|\overline{\lambda})I(o_t=v_k)}{\sum_{t=1}^TP(O,i_t=i|\overline{\lambda})} = \frac{\sum_{t=1,o_t=v_k}^T\gamma_t(i)}{\sum_{t=1}^T\gamma_t(i)} \]
至此,我们通过EM算法推出了参数更新公式,参数学习的问题就全部解决了。
预测算法
预测算法有两种,一个是近似算法,另一个是Viterbi算法。
近似算法
其实近似算法在讲单个状态的概率 \(\gamma_t(i)\) 的时候就已经提到了。
在每个时刻 \(t\) 选择在该时刻最有可能出现的状态 \(i_t^*\),从而得到一个状态序列 \(I^* = \{i_1^*, i_2^*, …, i_T^*\}\),将它作为预测结果。
我们已经知道单个状态的概率: \[ \gamma_t(i) =\frac{P(i_t=q_i,O|\lambda)}{P(O|\lambda)}=\frac{\alpha_t(i)\beta_t(i)}{\sum_{i=1}^N\alpha_t(i)\beta_t(i)} \] 直接选择概率最大的 \(i\) 作为最有可能的状态即可。
但是这么计算有个问题就是可能会出现此状态在实际中可能不会发生的情况。
Viterbi算法
Viterbi算法实际是用动态规划解HMM预测问题,用DP求概率最大的路径(最优路径),这时一条路径对应一个状态序列。
定义变量 \(\delta_t(i)\):在时刻 \(t\) 状态为 \(i\) 的所有路径中,概率的最大值。即: \[ \delta_t(i) = \max_{i_1,i_2, ..., i_{t-1}}P(i_t=i, i_{t-1}, ..., i_1, o_t, ..., o_1|\lambda) \] 初值: \[ \delta_1(i) = P(i_1=i,o_1|\lambda) = \pi_ib_{io_1} \] 递推: \[ \delta_{t+1}(i) =\max_{i_1,i_2, ..., i_{t}}P(i_{t+1}=i, i_{t}, ..., i_1, o_{t+1}, ..., o_1|\lambda) = \max_{1\leqslant j \leqslant N}(\delta_t(j)a_{ji})\cdot b_{io_{t+1}} \] 终止: \[ P^* = \max_{1\leqslant i \leqslant N}\delta_T(i) \] 最后求出来的 \(P^*\) 是最大概率路径的概率,若要知道具体是哪条路还需在递推时标记一下。
我们多想一点,看到这里的时候有木有觉得Viterbi算法和前向算法很像?如果你翻回去看一眼的话,就会发现Viterbi算法和前向算法唯一的区别就是把求和号 \(\sum\) 换成了取最大值 \(\max\) !是不是很有意思,其实数学里有很多这种情况,仅仅是换个符号就可以得到另一个很有用的结论!你有没有感受到数学之美呢?
总结
- HMM解决标注问题,在语音识别、NLP、生物信息、模式识别等领域被广泛使用。
- 如果观测状态是连续值,可将多项式分布改成高斯分布或高斯混合分布。
- 隐马尔可夫模型虽然有点难,但也非常好玩。
参考
李航,统计学习方法,清华大学出版社,2012
Christopher M. Bishop. Pattern Recognition and Machine Learning
Chapter 10. Springer-Verlag, 2006
Radiner L,Juang B. An introduction of hidden markov Models. IEEEASSP Magazine, 1986
Lawrence R. Rabiner. A tutorial on hidden Markov models andselected applications in speech recognition. Proceedings of theIEEE 77.2, pp. 257-286, 1989
Jeff A. Bilmes. A gentle tutorial of the EM algorithm and itsapplication to parameter estimation for Gaussian mixture andhidden Markov models. 1998.
https://en.wikipedia.org/wiki/Hidden_Markov_model