决策树简介
决策树(Decision tree)由一个决策图和可能的结果组成, 用来创建到达目标的规划。决策树建立并用来辅助决策,是一种特殊的树结构。决策树是一个利用像树一样的图形或决策模型的决策支持工具,包括随机事件结果,资源代价和实用性。它是一个算法显示的方法。决策树经常在运筹学中使用,特别是在决策分析中,它帮助确定一个能最可能达到目标的策略。如果在实际中,决策不得不在没有完备知识的情况下被在线采用,一个决策树应该平行概率模型作为最佳的选择模型或在线选择模型算法。决策树的另一个使用是作为计算条件概率的描述性手段。
機器學習中,決策樹是一個預測模型;他代表的是對象屬性與對象值之間的一種映射關係。樹中每個節點表示某個對象,而每個分叉路徑則代表的某個可能的屬性值,而每個葉結點則對應從根節點到該葉節點所經歷的路徑所表示的對象的值。決策樹僅有單一輸出,若欲有複數輸出,可以建立獨立的決策樹以處理不同輸出。 数据挖掘中决策树是一种经常要用到的技术,可以用于分析数据,同样也可以用来作预测。
构造决策树
在构造决策树时,我们需要解决的第一个问题就是,当前数据集上哪个特征在划分数据分类时取决定性作用。为了找到决定性特征,划分出最好的结果,我们必须评估每个特征。完成测试之后,原始数据集就被划分为几个数据子集。如果数据子集内的数据不属于同一类型,则需要重复划分数据子集的过程。
划分数据子集的伪代码 createBranch()如下所示:
1 | 检测数据集中的每个子项是否属于同一分类: |
可见创建决策树就是反复划分数据集的过程,那么如何划分数据集、何时停止划分就是决策树构造的关键,本文主要介绍ID3算法及其实现。
ID3 算法
概揽
ID3算法(Iterative Dichotomiser 3)是一个由Ross Quinlan发明的用于决策树的算法。
这个算法是建立在奥卡姆剃刀的基础上:越是小型的决策树越优于大的决策树。尽管如此,该算法也不是总是生成最小的树形结构。而是一个启发式算法。奥卡姆剃刀阐述了一个信息熵的概念:
\[I_E(i)=-\sum _{j=1}^{m}f(i,j)\log _2f(i,j)\]
这个ID3算法可以归纳为以下几点: * 使用所有没有使用的属性并计算与之相关的样本熵值 * 选取其中熵值最小的属性 * 生成包含该属性的节点
信息增益
划分数据集的最大原则是:将无序的数据变得更加有序。我们可以使用多种方法划分数据集,但是每种方法都有各自优缺点。组织杂乱无章的数据的一种方法就是使用信息论度量信息。
在划分数据集之前之后信息发生的变化称为信息增益,知道如何计算信息增益,我们就可以计算每个特征值划分数据集获得的信息增益,获得信息增益最高的特征就是最好的选择。
集合信息的度量方式被称为香农熵或简称熵。
熵(entropy)定义为信息的期望值,在明晰这个概念之前,我们必须知道信息的定义。如果待分类事务可能划分在多个分类之中,则符号 \(x_i\) 的信息定义为
\[l(x_i) = -log_2p(x_i)\] 其中 \(p(x_i)\) 是选择该分类的概率。
所以计算熵的公式为:
\[H = -\sum_{i=1}^np(x_i)log_2p(x_i)\] 其中 \(n\) 是分类的数目。
下面的Python代码将示例如何计算给定数据集的熵。
1 | from math import log |
把上述代码保存为 decisiontree.py,在为其添加一个创建数据集函数:
1 | def createDataSet(): |
在Python命令提示符下输入下列命令:
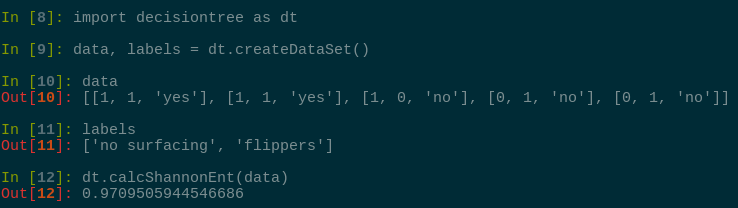
熵越高,则混合的数据也越多。得到熵之后,我们就可以按照获取最大信息增益的方法划分数据集。
划分数据集
我们将对每个特征划分数据集的结果计算一次信息熵,然后判断按照哪个特征划分是最好的方式。
在 decisiontree.py 中加入如下代码: 1
2
3
4
5
6
7
8def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
上述代码使用了三个输入参数:待划分数据集、划分数据集的特征、需要返回的特征的值。我们可以在前面的简单样本数据上测试函数 splitDataSet() 函数:

接下来我们将遍历整个数据集,循环计算熵,找到最好的划分方式,在 decisiontree.py 中添加如下函数:
1 | def chooseBestFeat(dataSet): |
在上述代码中调用的数据集需要满足一定的要求: 1. 数据必须是一种由列表元素组成的列表,而且所有元素都要具有相同的数据长度 2. 数据的最后一列或者每个实例的最后一个元素是当前类的标签
现在我们可以测试上面代码的实际输出结果: 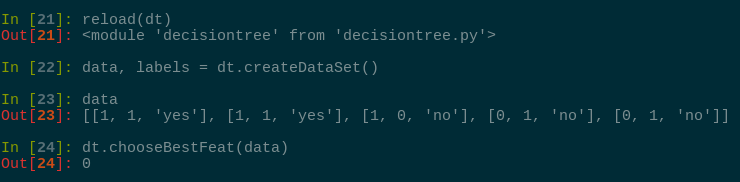
代码的运行结果告诉我们,第0个特征是最好的用于划分数据集的特征,划分的正确性请读者自行检验。
递归构建决策树
目前我们已经学习了从数据集构造决策树算法所需的所有子功能模块,下面我们采用递归的原则构建整个决策树。
递归结束的条件是:程序遍历完所有划分数据集的属性,或者每个分支下的所有实例都具有相同的分类。
如果数据集已经处理了所有属性,但类标签依然不是唯一的,此时我们需要决定如何定义该叶子节点,在这种情况下,我们通常会采用多数表决的方法决定叶子节点的分类。
打开文本编辑器,添加如下代码到 decisiontree.py 中: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32import operator
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCnt = sorted(classCount.iteritems(),
key=operator.itemgetter(1), reverse=True)
return sortedClassCnt[0][0]
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
# 类别完全相同时,停止继续划分
return classList[0]
if len(dataSet[0]) == 1:
# 遍历完所有特征时返回出现最多的
return majorityCnt(classList)
bestFeat = chooseBestFeat(dataSet)
bestFeatLabel = labels[bestFeat]
DTree = {bestFeatLabel: {}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
DTree[bestFeatLabel][value] = createTree(
splitDataSet(dataSet, bestFeat, value), subLabels)
return DTree
这里使用python的字典类型存储树的信息,当然也可以定义特殊类型的数据结构,但在这里完全没有必要。
我们测试一下上述代码的实际输出结果:
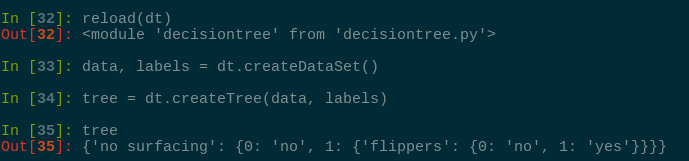
变量 tree 包含了很多代表树结构的嵌套字典。如果值是类标签,则该节点是叶子节点; 如果值是另一个字典,则该子节点是一个判断节点,这种格式结构不断重复就形成了一棵树。本例中这棵树包含了3个叶子节点以及两个判断节点,如下所示:

总结
决策树分类器就像带有终止块的流程图,终止块表示分类结果。开始处理数据集时,我们首先要测量集合中数据的不一致性,也就是熵,然后寻找最优方案划分数据集,直到数据集中的所有数据属于同一分类。ID3算法可用于划分标称型数据集。构建决策树时,我们通常采用递归的方法将数据集转化为决策树。
还有其他决策树构造算法,最流行的是C4.5和CART,详情见下回分解。
参考
《机器学习实战》[美] Peter Harrington https://www.wikiwand.com/en/ID3_algorithm https://www.wikiwand.com/en/Decision_tree