Deep Q-Network
Deep Q-Network (DQN) 是由DeepMind的Mnih等人于2013年提出的算法,该算法成功把深度学习应用到了RL领域,并(一定程度上)解决了训练不稳定的问题,在玩Atari游戏中取得了非常好的结果。
文章指出使用非线性函数拟合 Q-value 的RL算法不稳定主要因为:
- 同一个观测序列中的数据相关性较大
- 当 Q-value 发生了很小的改变,可能导致整个策略(policy)发生较大变化,从而导致 Q-value 和目标 \(r + \gamma * \max_{a'}Q(s' ,a')\) 的差距不稳定
DQN使用了两个trick来解决上述问题:
- Experience replay
- 使用经验池缓存数据,每次训练时从经验池里sample数据,从而降低训练数据之间的相关性
- Two Q networks
- 一个网络用来生成 Q-target,另一个网络进行探索;每隔一定时间两个网络进行同步
- 这样使得 Q-target 相对稳定
整体算法

Asynchronous Actor Critic
Asynchronous Actor Critic (A3C) 也是由DeepMind的Mnih等人提出的算法,于2016年发表在ICML上。不同于DQN的是,A3C属于策略梯度(Policy Gradient)类算法,而DQN是基于value的;相同的是,A3C也在Atari游戏上取得了非常好的结果(强于DQN)。
使用上述经验池有以下问题:
- 使用更多的内存和计算资源
- 只能使用 off-policy 的RL算法(学习 old policy 产生的数据)
为了使用 on-policy 算法,文章提出了使用异步学习代替经验池的方法,同时也能保持算法的稳定性,其中使用最广泛的是A3C算法,它具有以下特点:
- 并行地使用多个 agent 在各自的环境里探索,每个 agent 在同一时刻探索的内容各不相同,从而降低了数据相关性
- 在CPU上训练更加高效
整体算法
- 同步线程专属网络(\(\theta', \theta_v'\))和全局网络(\(\theta, theta_v\))
- 每个 agent 使用线程专属网络各自进行探索
- 根据线程专属网络计算梯度:\(d\theta, d\theta_v\)
- 使用 \(d\theta, d\theta_v\) 更新全局网络(\(\theta, theta_v\))
- 回到第一步

其他细节
- 主线程向子线程传参数,子线程向主线程传梯度
- agent 和 critic 共用一个网络,输出分为两头
- 增加了熵正则化(鼓励探索)
- \(\triangledown_{\theta'}\log\pi(a_t|s_t;\theta')(R_t-V(s_t;\theta_v))+\beta\triangledown_{\theta'}H(\pi(s_t; \theta'))\)
- \(H(X) = E[-\log P(X)]\)
- 代码参考:https://github.com/NeymarL/Pacman-RL/blob/master/src/a3c.py
- 注:计算 policy loss 中的 advantage 的时候不能保留其梯度,否则 policy 的梯度会流入 value network 中,产生bug
Generalized Advantage Estimator
Generalized Advantage Estimator (GAE) 是由伯克利大学的Schulman等人于2016年提出的一种新的估计优势函数(Advantage function)的方法。
我们的目标是定义优势函数 \(A^\pi(s_t, a_t)\) 使其用来计算策略梯度: \[ \hat{g}=\mathbb{E}_{s_0, a_0...\sim\pi_\theta}[\sum_{t=0}^\infty A^\pi_t(s_t,a_t)\triangledown_\theta\pi_\theta(a_t|s_t)] \] 优势函数的定义为: \[ A^\pi(s_t, a_t) = Q^\pi(s_t, a_t) - V^\pi(s_t) \] 我们使用 \(V\) 来近似价值函数(value function),那么 TD(0) error \(\delta_t^V = r_t +\gamma V(s_{t+1}-V(s_t))\) 就是优势函数的一个估计,并且如果 \(V = V^\pi\),则 \(\delta_t^V\) 是 \(A^\pi\) 的一个无偏估计: \[ \begin{align} \mathbb{E}_{s_{t+1}}[\delta_t^{V^\pi}]&=\mathbb{E}_{s_{t+1}}[r_t+\gamma V^\pi(s_{t+1})-V^\pi(s_t)]\\ &= \mathbb{E}_{s_{t+1}}[Q^\pi(s_t,a_t)-V^\pi(s_t)]\\ &= A^\pi(s_t,a_t) \end{align} \] 只要 \(V\) 是近似的,TD(0) error就是优势函数的一个有偏估计,那么TD(\(\lambda\)) error又如何呢?
顺着这个思路,我们可以多往后看几步: \[ \begin{array}{lcl} \hat{A}_t^{(1)}&:=\delta_t^V&=-V(s_t)+r_t+\gamma V(s_{t+1})\\ \hat{A}_t^{(2)}&:=\delta_t^V + \gamma\delta_{t+1}^V&=-V(s_t)+r_t+\gamma r_{t+1}+\gamma^2 V(s_{t+2})\\ \hat{A}_t^{(3)}&:=\delta_t^V + \gamma\delta_{t+1}^V+\gamma^2\delta_{t+2}^V &=-V(s_t)+r_t+\gamma r_{t+1}+\gamma^2 r_{t+2} +\gamma^2 V(s_{t+3}) \\ \end{array} \]
\[ \hat{A}_t^{k}:=\sum_{l=0}^{k-1}\gamma^l\delta_{t+l}^V=-V(s_t)+r_t+\gamma r_{t+1}+...+\gamma^{k-1}r_{t+k-1}+\gamma^kV(s_{t+k}) \]
可以看到,虽然 \(\hat{A}_t^{(k)}\) 依旧是有偏估计,但是偏差随着 \(k\) 的增大在逐渐减小,因为 \(\gamma^kV(s_{t+k})\) 这一项衰减的越来越厉害。当 \(k\rightarrow\infty\) 时: \[ \hat{A}_t^{(\infty)}=\sum_{l=0}^\infty\gamma^l\delta_{t+l}^V=-V(s_t)+\sum_{l=0}^\infty\gamma^lr_{t+l} \] 可以看到就是 return 减去 baseline。
\(\text{GAE}(\lambda)\) 的定义为这些 \(k\) 步估计的指数平均,即 TD(\(\lambda\)) error: \[ \begin{align} \text{GAE}_t(\lambda)&:=(1-\lambda)(\hat{A}_t^{(1)}+\lambda\hat{A}_t^{(2)}+\lambda^2\hat{A}_t^{(3)}+...)\\ &=(1-\lambda)(\delta_t^V+\lambda(\delta_t^V-\gamma\delta_{t+1}^V)+...)\\ &=\sum_{l=0}^\infty(\gamma\lambda)^l\delta_{t+l}^V \end{align} \] 代码实现
1 | # rews : rewards, vals: values, lam: lambda |
1 | def discount_cumsum(x, discount): |
其他
Batch-Normalization
解决网络层数变多梯度消失/爆炸问题
- 梯度截断
- 初始化
- RELU
对每层神经元处理结果进行归一化,但又不能破坏上一层提取的特征(变换重构,引入了可学习参数\(\gamma, \beta\))
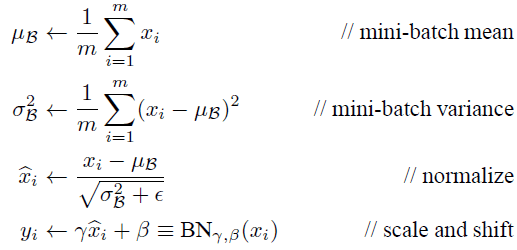
Inference时 \(\mu_B\) 和 \(\sigma^2_B\) 固定。
为什么不用白化?
- 在模型训练过程中进行白化操作会带来过高的计算代价和运算时间
在BN中,是通过将activation规范为均值和方差一致的手段使得原本会减小的activation的scale变大。 \[ \frac{\partial h_l}{\partial h_{l-1}} = \frac{\partial BN(w_l h_{l-1})}{\partial h_{l-1}} = \frac{\partial \alpha w_l h_{l-1}}{\partial h_{l-1}} \] 其中 \(\alpha\) 指缩放。可以看到此时反向传播乘以的数不再和 \(w\) 的尺度相关,也就是说尽管我们在更新过程中改变 \(w\) 的值,但是反向传播的梯度却不受影响。
Activation Layers
ReLU
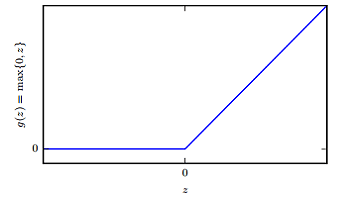
整流线性单元易于优化,因为它们和线性单元非常类似。线性单元和整流线性单元的唯一区别在于整流线性单元在其一半的定义域上输出为零。这使得只要整流线性单元处于激活状态,它的导数都能保持较大。它的梯度不仅大而且一致。整流操作的二阶导数几乎处处为 0,并且在整流线性单元处于激活状态时,它的一阶导数处处为 1。这意味着相比于引入二阶效应的激活函数来说,它的梯度方向对于学习来说更加有用。
ReLU 的过程更接近生物神经元的作用过程
Leaky ReLU
ReLU 及其扩展都是基于一个原则,那就是如果它们的行为更接近线性,那么模型更容易优化。 \[ g(z; \alpha) = \max(0, z) + \alpha \min(0, z) \] \(\alpha\) 为固定值或可学习参数。
Sigmoid & Tanh
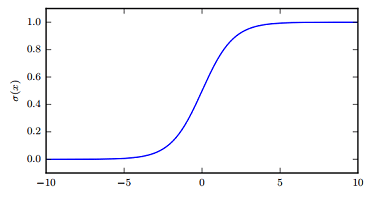 \[
g(z) = \frac{1}{1 + e^{-z}}
\]
\[
g(z) = \frac{1}{1 + e^{-z}}
\]
- sigmoid 常作为输出单元用来预测二值型变量取值为 1 的概率
- sigmoid 函数在输入取绝对值非常大的正值或负值时会出现饱和(saturate)现象,在图像上表现为开始变得很平,此时函数会对输入的微小改变会变得不敏感。仅当输入接近 0 时才会变得敏感。从而使得学习变困难。
- 如果要使用 sigmoid 作为激活函数时(浅层网络),tanh 通常要比 sigmoid 函数表现更好。
Bagging
思想:多个模型平均效果好于单个模型
Bagging(bootstrap aggregating)是通过结合几个模型降低泛化误差的技术 (Breiman, 1994)。
具体来说,Bagging 涉及构造 k 个不同的数据集。每个数据集从原始数据集中重复采样构成,和原始数据集具有相同数量的样例。这意味着,每个数据集以高概率缺少一些来自原始数据集的例子,还包含若干重复的例子(更具体的,如果采样所得的训练集与原始数据集大小相同,那所得数据集中大概有原始数据集 2/3 的实例)
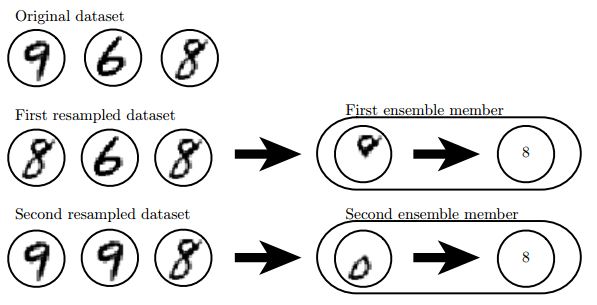
第一个分类器学到上面的圆圈就会认为数字是8,第二个分类器检测到下面的圈就会认为数字是8,把两个结合起来就知道只有当上下都有圈(置信概率最大)的时候数字才是8。
Dropout
简单来说,Dropout (Srivastava et al., 2014) 通过参数共享提供了一种廉价的 Bagging 集成近似,能够训练和评估指数级数量的神经网络。
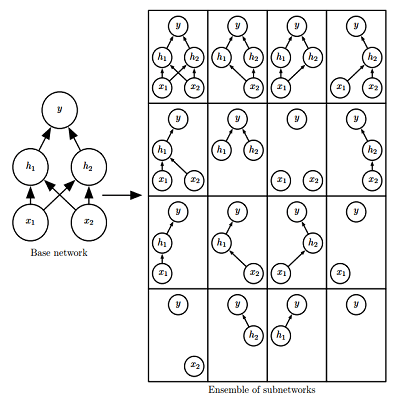
Dropout与Bagging的不同点:
- Bagging 为串行策略;Dropout 为并行策略
- 在 Bagging 的情况下,所有模型都是独立的;而在 Dropout 的情况下,所有模型共享参数,其中每个模型继承父神经网络参数的不同子集。
- 在 Bagging 的情况下,每一个模型都会在其相应训练集上训练到收敛。而在 Dropout 的情况下,通常大部分模型都没有显式地被训练;取而代之的是,在单个步骤中我们训练一小部分的子网络,参数共享会使得剩余的子网络也能有好的参数设定。