Now we are switching from regression problems to classification problems. Don't be confused by the name "Logistic Regression"; it is named that way for historical reasons and is actually an approach to classification problems, not regression problems.
- Classification
- Hypothesis Representation
- Decision Boundary
- Cost Function
- Simplified Cost Function and Gradient Descent
- Advanced Optimization
- Multiclass Classification: One-vs-all
Classification
Instead of our output vector \(y\) being a continuous range of values, it will only be 0 or 1. \[y∈\{0,1\}\]
Where 0 is usually taken as the "negative class" and 1 as the "positive class", but you are free to assign any representation to it.
We're only doing two classes for now, called a "Binary Classification Problem."
One method is to use linear regression and map all predictions greater than 0.5 as a 1 and all less than 0.5 as a 0. This method doesn't work well because classification is not actually a linear function.
Hypothesis Representation
Our hypothesis should satisfy: \[0≤h_θ(x)≤1\]
Our new form uses the "Sigmoid Function", also called the "Logistic Function": \[hθ(x)=g(θ^Tx)\] \[z=θ^Tx\] \[g(z)=\frac{1}{1+e^{−z}}\]
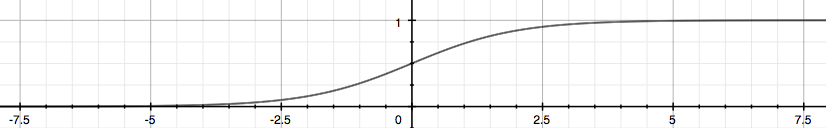
The function \(g(z)\), shown here, maps any real number to the (0, 1) interval, making it useful for transforming an arbitrary-valued function into a function better suited for classification. Try playing with interactive plot of sigmoid function here.
We start with our old hypothesis (linear regression), except that we want to restrict the range to 0 and 1. This is accomplished by plugging \(θ^Tx\) into the Logistic Function.
\(h_θ\) will give us the probability that our output is 1. For example, \(h_θ(x)=0.7\) gives us the probability of 70% that our output is 1.
\[h_θ(x)=P(y=1∣x ;θ)=1−P(y=0∣x ;θ)\] \[P(y=0∣x;θ)+P(y=1∣x ;θ)=1\] Our probability that our prediction is 0 is just the complement of our probability that it is 1 (e.g. if probability that it is 1 is 70%, then the probability that it is 0 is 30%).
Decision Boundary
In order to get our discrete 0 or 1 classification, we can translate the output of the hypothesis function as follows:
\[h_θ(x)≥0.5→y=1\] \[h_θ(x)<0.5→y=0\]
The way our logistic function \(g\) behaves is that when its input is greater than or equal to zero, its output is greater than or equal to 0.5:
\[g(z)≥0.5\] when \(z≥0\)
Remember.-
\[z=0,e^0=1,g(z)=1/2\] \[z→∞,e^{−∞}→0,g(z)=1\] \[z→−∞,e^∞→∞,g(z)=0\]
So if our input to g is \(θ^TX\), then that means:
\[h_θ(x)=g(θ^Tx)≥0.5\] when\(θ^Tx≥0\)
From these statements we can now say:
\[θ^Tx≥0→y=1\] \[θ^Tx<0→y=0\]
The decision boundary is the line that separates the area where y=0 and where y=1. It is created by our hypothesis function.
Example:
\[θ=\begin{bmatrix} 5 \\ -1 \\ 0\\ \end{bmatrix}\] \(y=1\) if \(5+(−1)x1+0x2≥0\) \(5−x1≥0\) \(−x1≥−5\) \(x1≤5\)
Our decision boundary then is a straight vertical line placed on the graph where \(x_1=5\), and everything to the left of that denotes \(y=1\), while everything to the right denotes \(y=0\).
Again, the input to the sigmoid function \(g(z)\) (e.g. \(θ^TX\)) need not be linear, and could be a function that describes a circle (e.g. \(z=θ_0+θ_1x^2_1+θ_2x^2_2\)) or any shape to fit our data.
Cost Function
We cannot use the same cost function that we use for linear regression because the Logistic Function will cause the output to be wavy, causing many local optima. In other words, it will not be a convex function. Instead, our cost function for logistic regression looks like:
\[J(θ)=\frac{1}{m}∑_{i=1}^mCost(h_θ(x^{(i)}),y^{(i)})\]
\(Cost(h_θ(x),y)=−log(h_θ(x))\) if \(y = 1\) $Cost(h_θ(x),y)=−log(1−h_θ(x)) $ if \(y = 0\)
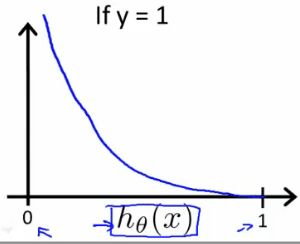
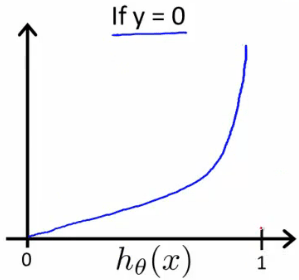
The more our hypothesis is off from \(y\), the larger the cost function output. If our hypothesis is equal to \(y\), then our cost is \(0\):
\(Cost(h_θ(x),y)=0\) \(if\) \(h_θ(x)=y\) \(Cost(h_θ(x),y)→∞\) \(if\) \(y=0\) \(and\) \(h_θ(x)→1\) \(Cost(h_θ(x),y)→∞\) \(if\) \(y=1\) \(and\) \(h_θ(x)→0\)
If our correct answer '\(y\)' is 0, then the cost function will be 0 if our hypothesis function also outputs 0. If our hypothesis approaches 1, then the cost function will approach infinity.
If our correct answer '\(y\)' is 1, then the cost function will be 0 if our hypothesis function outputs 1. If our hypothesis approaches 0, then the cost function will approach infinity.
Note that writing the cost function in this way guarantees that \(J(θ)\) is convex for logistic regression.
Simplified Cost Function and Gradient Descent
We can compress our cost function's two conditional cases into one case:
\[Cost(h_θ(x),y)=−ylog(h_θ(x))−(1−y)log(1−h_θ(x))\]
Notice that when y is equal to 1, then the second term \(((1−y)log(1−h_θ(x)))\) will be zero and will not affect the result. If y is equal to 0, then the first term \((−ylog(h_θ(x)))\) will be zero and will not affect the result.
We can fully write out our entire cost function as follows:
\[J(θ)=−\frac{1}{m}\sum_{i=1}^m[y^{(i)}\log(h_θ(x^{(i)}))+(1−y^{(i)})\log(1−h_θ(x^{(i)}))]\]
A vectorized implementation is:
\[J(θ)=−\frac{1}{m}(\log(g(Xθ))^Ty+\log(1−g(Xθ))^T(1−y))\]
Gradient Descent
Remember that the general form of gradient descent is: \(Repeat\{\) \[θ_j := θ_j−α\frac{∂}{∂θ_j}J(θ)\] \(\}\)
We can work out the derivative part using calculus to get: \(Repeat\{\) \[θ_j := θ_j−\frac{α}{m}\sum_{i=1}^m(h_θ(x^{(i)})−y^{(i)})x^{(i)}_j\] \(\}\)
Notice that this algorithm is identical to the one we used in linear regression. We still have to simultaneously update all values in theta.
A vectorized implementation is:
\[θ :=θ − \frac{α}{m}X^T(g(Xθ)− \overrightarrow{y} )\]
Advanced Optimization
"Conjugate gradient", "BFGS", and "L-BFGS" are more sophisticated, faster ways to optimize theta instead of using gradient descent. A. Ng suggests you do not write these more sophisticated algorithms yourself (unless you are an expert in numerical computing) but use them pre-written from libraries. Octave provides them.
We first need to provide a function that computes the following two equations:\(J(θ)\), \(\frac{∂}{∂θ_j}J(θ)\)
We can write a single function that returns both of these: 1
2
3
4function [jVal, gradient] = costFunction(theta)
jval = [...code to compute J(theta)...];
gradient = [...code to compute derivative of J(theta)...];
end
Then we can use octave's "fminunc()" optimization algorithm along with the "optimset()" function that creates an object containing the options we want to send to "fminunc()". (Note: the value for MaxIter should be an integer, not a character string - errata in the video at 7:30) 1
2
3options = optimset('GradObj', 'on', 'MaxIter', 100);
initialTheta = zeros(2,1);
[optTheta, functionVal, exitFlag] = fminunc(@costFunction, initialTheta, options);
We give to the function "fminunc()" our cost function, our initial vector of theta values, and the "options" object that we created beforehand.
Multiclass Classification: One-vs-all
Now we will approach the classification of data into more than two categories. Instead of \(y = \{0,1\}\) we will expand our definition so that \(y = \{0,1...n\}\).
In this case we divide our problem into \(n+1\) (+1 because the index starts at 0) binary classification problems; in each one, we predict the probability that '\(y\)' is a member of one of our classes.
\[y∈\{0,1...n\}\] \[h^{(0)}_θ(x)=P(y=0∣x ;θ)\] \[h^{(1)}_θ(x)=P(y=1∣x ;θ)\] \[⋯\] \[h^{(n)}_θ(x)=P(y=n∣x ;θ)\] \[prediction=\max_i(h^{(i)}_θ(x))\]
We are basically choosing one class and then lumping all the others into a single second class. We do this repeatedly, applying binary logistic regression to each case, and then use the hypothesis that returned the highest value as our prediction.